
GraphQLはなぜ開発体験が良いのか?モノづくり産業のDXに挑戦しているキャディに聞きました【技術選定の裏側:GraphQL編 vol.3】

モダンな技術の活用法に迫る、エンジニア座談会企画!第1弾、2弾に続き「GraphQL」の魅力に迫ります。
***
モノづくり産業(製造業)のDXに挑戦しているキャディ株式会社。2017年11月の創業以来、右肩上がりで成長し、2021年8月にはシリーズBで総額80.3億円の資金調達を実施するなど、会社規模・事業ともに拡大を続けています。
今回はモダンな技術にも積極的に挑戦しているキャディ株式会社より、フロントエンドエンジニアの桐生さん、菅さん、山田さんの3名をお招きし、GraphQLのメリットやデメリット、今後の展望についてお伺いしました。
■登場人物プロフィール
キャディ株式会社 フロントエンドエンジニア 桐生 達嗣
新卒でSIerに入社。toB系のシステム開発に携わり、上流から下流まで工程全般を経験。その後、Webフロントエンドに興味を惹かれ、UI/UXに強みのある受託開発企業へ。社内のWebフロントエンド開発全般を牽引。数年後、外資系UIコンポーネントベンダーへ転職し、クライアントへのUIコンポーネントの導入や、Web技術コンサルティングを実施。
社会に対してより直接的に貢献できる仕事をしたいと思っていたところキャディと出会い、2019年10月にジョイン。
キャディ株式会社 フロントエンドエンジニア 菅 圭祐
新卒でソーシャルゲーム部門に配属され、バックエンドエンジニアとして開発等を担当。その後データ分析ツールやその他複数のスタートアップへ参画。
キャディへ入社後は、フロントエンド開発およびBFFサーバーの開発等を担当。
キャディ株式会社 フロントエンドエンジニア 山田悠暉
2017年ウォンテッドリー株式会社に新卒入社。ビジネスSNS・Wantedly Visit や名刺管理アプリ Wantedly People のサービス開発、インフラチームでの基盤開発などさまざまなチー
ムを経験。開発組織全体のフロントエンドのリードを担当。
製造業という事業領域の面白さと新しいことへの挑戦を期待して、2021年1月にキャディに入社。現在は原価計算システムのフロントエンドやバックエンドなどに広く携わっている。

▲今回取材を受けてくださった、左から菅さん、桐生さん、山田さん
マイクロサービスを束ねるBFFにGraphQLを採用
──アーキテクチャについてお聞かせいただけますか。
桐生:私のチームでは、フロントエンドのレイヤー、BFFのレイヤー、バックエンドのレイヤーという構造にしていて、GraphQLはフロントエンドとBFF間のプロトコルとして使用しています。フロントエンドではReactを採用し、ApolloでGraphQLの実装をしている形ですね。バックエンドはRustで、gRPCを使い通信しています。
菅:社内ではGraphQLをエンドポイントとするフロントエンド向けのサーバーをBFFとして構築し、裏側のマイクロサービスはgRPCを使って通信するといった構成が多いですね。しかし、私達はまだ立ち上げたばかりのサービスを担当しており、一部のマイクロサービスに関しては、REST APIで通信しています。
社内全体としては、共通のマイクロサービスに依存していながらも、それぞれのサービスに合わせてBFFを構築したり、技術スタックを選択したりしていますね。
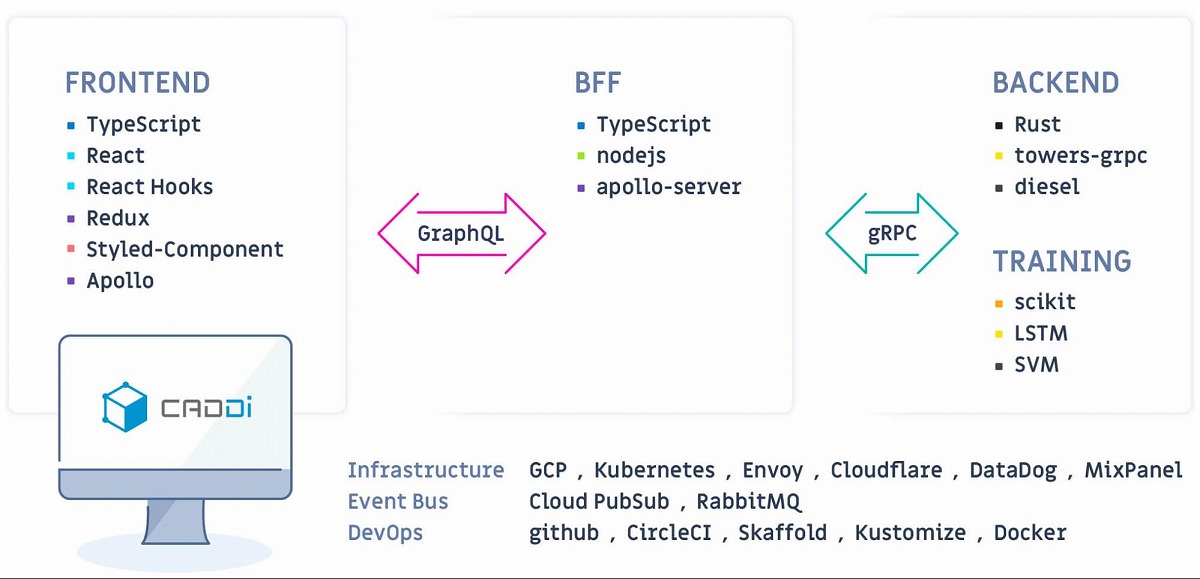
キャディのアーキテクチャ(CADDi ENGINEER Tech Blog、CADDi Tech Stackより引用)
──大まかには統一されているものの、プロジェクトごとにさまざまなアーキテクチャを構築されているのですね。会社としてGraphQLを導入された理由はなんだったのでしょう?
桐生:私が入社した2019年の10月ごろから開発を内製化するプロジェクトがスタートし、社内のメンバーでアーキテクチャについて考えている際に、バックエンドをマイクロサービス化し、それらを束ねるBFFの層を作ることが決まりました。その時に「GraphQLって便利そうだよね」という話が出て、メンバーにモダンな技術を使いたい願望があったため、GraphQLを導入することになりました。
──なるほど。ちなみにライブラリについては、どのように選定されたのでしょうか。
桐生:比較対象のRelayと比べたときに、Local Stateの使い勝手や学習コストの低さ、またコミュニティの大きさなどを考慮して、Apolloの方がメリットが大きいと思ったからですね。
▲今回の取材はオンラインで実施しました
クライアント側からレスポンスをコントロールでき、開発体験は良い
──GraphQLを使ってみて感じるメリットはどんなところですか?
桐生:レスポンスの形をUI側でコントロールできる点は、とても大きなメリットだと感じています。取りたいフィールドを取捨選択した上で適切な形で値を取得できますし、オーバーフェッチングを防ぐことが出来ます。
菅:私個人としては、クライアントとバックエンドの両方を開発する人にとっては、コントロールしやすい技術スタックだと思っています。クライアント側からバックエンドのパフォーマンスを意識してクエリの組み立てをコントロールできますし、RESTと比べてもメリットがあると感じますね。
パフォーマンス面では、バックエンドがRDBの場合にテーブルをまたいだクエリを発行する際、適切にJOINしてレスポンスを返すなど、工夫をしています。
──なるほど。山田さんはいかがでしょうか?
山田:エンドポイントがGraphQLだけに統一される点はメリットだと思います。GraphQLのクエリをエンドポイントに投げるだけでデータを取得できますし、リソースを取得する際に、対応するエンドポイントを探す必要がありません。
またフィールドやリゾルバーの仕様変更に基づく型の変更があった際、ライブラリ経由で安全かどうか確認する機能が備わっているのも嬉しいです。
──ライブラリの使い勝手についてもお話いただけますか。
山田:Apollo Clientについては、ネットワークレイヤーやローカルレイヤーのキャッシュをマージして扱えますし、とても便利だと思います。
桐生:キャッシュを扱える点については、フロントエンドのアーキテクチャ的にもメリットがあると個人的には思っています。データをどこにストアするのか考える必要がなくなったと言いますか。極論、コンポーネントの設計だけ考えればいいといった感じですね。
菅:REST APIでは実行順序を考慮したり、非同期のレスポンスによりレンダリングをコントロールしたりする必要があります。しかし、GraphQLのエンドポイントが一つになることでデータを集合的に取れるため、ライフサイクルをシンプルにすることができますね。
──開発効率を向上することができるんですね。反対に、GraphQLで課題を感じる部分はありますか?
桐生:私はキャディに入社してから初めてGraphQLを触ったため、学習コストが発生してしまった点は否めません。
またGraphQLを一言で表すと、データを数珠繋ぎにしてくれるような仕組みだと思うのですが、そこを理解していないとアンチパターンに陥る可能性もあります。グラフ構造を意識せず、散らばったデータをまとめて返すといった実装をすると、RESTを使用した時と差異がないため、GraphQLの“旨み”を活かせないんです。
GraphQLのスキーマ設計には工夫が必要だと思いますし、私たちもまだ最適解を探している途中ですね。
──最適解が見つかっていないのは、モダンな技術ならではの課題かもしれませんね。
菅:そうですね。GraphQLを使って一番初めにつまずくものは、認証付きAPIだと思います。認証用のトークンを取得するAPIを提供する場合、GraphQLで認証を通してしまうと、GraphQLで定義されているスキーマの実行順序をコントロールできなくなるんです。パラレルでバックエンド上から実行されてしまうため、認証が前提になったクエリを発行しようと思うと、クライアントサイドが先に認証を取得した状態でGraphQLを実行するしかないといった制約になってしまう。
公式では、認証用のトークンはGraphQLのエンドポイントではなく、別のもので生成することが推奨されています。このように、実行順序で結果が変わってしまうものについては、GraphQLを使う上で注意が必要な部分ですね。
また、バックエンドデータのキャッシュについては、まだ仕組みがうまく出来ていません。データベースにアクセスが行ってしまう点も注意が必要です。
山田:“旨み”を活かすという意味では、私が担当しているプロダクトはPCのみで画面にアクセスすることを想定しているので、先ほど桐生さんがGraphQLのメリットでおっしゃっていた、フィールドの選択的な取得は活かせていないかもしれません。
定義されたフィールドが本当に使われているかどうか判断できないため、視覚化したり、不要なフィールドを安全に消したり出来れば良いなと思っています。
また、gRPCのProtocol Buffersで定義されたスキーマをGraphQLで再定義する必要があるのも課題だと感じています。ゆくゆくは、BFFで自動生成されるようになってほしいですね。
──なるほど。GraphQLを使っていて「これは失敗だった」という経験があれば、お話しいただけますか。
桐生:実装を間違えて、バックエンドに対して高負荷な状態を作り出してしまったことがあります。フロントで必要なデータを取得するためにスキーマを定義して、BFFの方で取得できるように実装したことがあり、結果としてバックエンドに大量のリクエストが飛んでしまいました。いわゆるN+1問題と呼ばれているものですね。フロントで欲しかった一覧のデータが、BFF的にはバックエンドに対して一つひとつのデータのリクエストを投げるといった形になってしまい、パフォーマンスの遅延をもたらしてしまって……。
そういったことを解決するためにDataLoaderがあることは知っていましたし、他のクエリでは使用しています。ただ、新しく改修しようとしていたところにはDataLoaderを使っておらず、実装した後にそれが判明したという手痛い失敗がありますね。

▲社内の様子
キャディでは、今後もモダンな技術を積極的に取り入れていく
──最後に今後の展望をお伺いできればと思うのですが、いかがでしょうか?
桐生:いくつかありまして、一つはFragment Colocationに則った実装にするということ。Fragment Colocationは、GraphQLのクエリとフロントエンドのコンポーネントを一緒に配置するといった思想です。GraphQLはクエリのレスポンスに関するデータの形はクライアントが決定しているため、クエリとコンポーネントを可能な限り近くに置いておくことにより、コンポーネントが必要としているデータを明確にできるんです。現状では、クエリするファイルとコンポーネントを別々のディレクトリに配置しているため、より密接な形にしていきたいと考えています。
もう一つは、urqlへの挑戦ですね。ReactにSuspenseという機能がありますが、Apolloはまだ対応していません。新プロダクトの開発も進めていて、そちらではSuspenseに対応しているurqlを試験的に導入する予定です。
菅:私はGraphQLに似ていると評判のSupabaseが気になっています。キャディではFirebaseを使うことがあるため、そういった実験的なプロダクトを開発する際に役立つと思いますし、今後使ってみたい技術ですね。
山田:昨年あたりに、Specificationとして@deferや@streamといったディレクティブが入って、GraphQL.jsに`experimental-stream-defer` というバージョンタグでリリースされているんですよ。その安定化を2022年中にやってくれることを期待していて、もし実行されたら利用してみて、会社としてコミュニティに還元していきたいと思っています。
──技術に投資されているキャディだからこそ出てくる意見だと感じました。貴重なお話をお聞かせいただきありがとうございました!