
完全自動運転の実現にソフトウェア開発の技術を! ペタバイト級の走行データからつくる自動運転基盤の裏側

完全自動運転の実現を目指すTuring株式会社。名人に勝利した将棋AI Ponanzaの開発者山本一成さんと、米カーネギーメロン大学で自動運転開発に従事した青木俊介さんの共同創業で、生成AIと機械学習を軸に、完全自動運転・レベル5の実現を目指しています。
彼らが掲げるミッションは「We Overtake Tesla」。2025年末には人間の介入なしで東京の街を30分間運転する「Tokyo30」をマイルストーンに、End to End(以下、E2E)機械学習モデルの開発スピードを高めており、そのためにはソフトウェアエンジニアの力が欠かせないと言います。
そこで同社のソフトウェアエンジニア安本さんに、ソフトウェア開発がいかに自動運転MLモデル開発に寄与するのか、その役割や重要性を聞きました。
プロフィール
E2Eチーム
安本雅啓さん
新卒で日立製作所に入社し、鉄道ITシステムの研究開発に従事。その後AIスタートアップのアラヤにて開発案件に従事・CTOに就任。2021年4月にatama plusへ入社し、アルゴリズム開発エンジニアとしてAI教材atama+のレコメンドエンジンの開発を担当。2024年5月にチューリングに参画し、E2Eチームでソフトウェアエンジニアとして活躍中。
自動運転MLモデルの全体像とソフトウェア開発の役割

画像提供:Turing株式会社
― 大規模システム開発やAI開発、役職としてはCTOもご経験された安本さんが、Turingにご入社を決めた理由を教えてください。
最大の理由は、自動運転というドメインの魅力です。僕は元々ペーパードライバーで、自動運転の時代を待っていたんですよね。世の中的にはAIの発展が話題にされていますが、現在の画像認識AIの利活用シーンとしては工場での異常検出などが主流で、僕たちの身の回りの生活が劇的に変わっているわけではないなと思っていました。
またこれまで携わってきたSaaSプロダクトなどでは、ユーザー目線に立っているものの、真には同じ目線になりきれません。そういったものと比べると、自動運転は自分がユーザーになるし、僕たちの生活を劇的に変えてくれます。家族からも「おお!すごい!」と言ってもらえる、それくらい身近なドメインです。
またソフトウェア開発の分野で、車ほどの大きな実機が動くのは他にない体験ですよね。これまでのMLとソフトウェア開発の知識と経験が、自動運転のMLモデルをつくる周辺部分に生かせるかなと思って、入社を決めました。
― 自動運転MLモデル開発において、ソフトウェアエンジニアとしてはどのような貢献ができるのでしょうか?
僕たちの最終的なゴールは、自動運転のためのニューラルネットワークモデルをつくることです。そのためには良質な学習データを用意して、それをニューラルネットワークに学習させることが必要です。一例としては良質な学習データを収集し整理するという部分で、ソフトウェア開発の経験を生かしてML開発の高速化に貢献できていると思います。
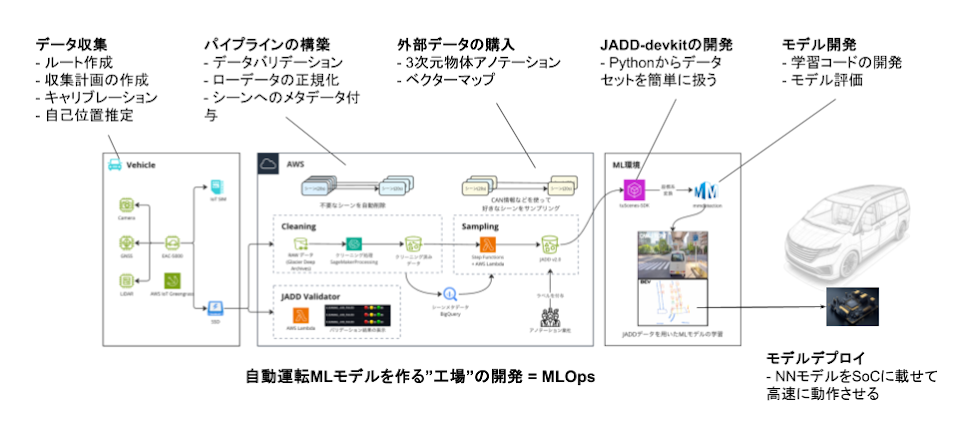
画像提供:Turing株式会社
― ここで言う“良質な学習データ”とは、どのようなデータなのでしょうか?
良質な学習データとは、量・質・多様性の3つの要素で定義しています。まず機械学習においてデータ量は多ければ多いほどよいので、当社では4万時間分の自動車走行データを集めようとしています。次にデータの質ですが、車載カメラの映像データやセンサーデータは、ハードウェアの影響で壊れていたりうまく読み込めないケースもあるので、そうした不具合のあるデータを省き学習に使える品質を担保することが大切です。最後に多様性ですが、街の様子や天気の違い、イレギュラーな交通整理や飛び出し事例など、さまざまなパターンのデータが必要です。
このような“良質な学習データ”を用意するために、5〜6台のデータ収集車が都内を走り回り、毎日合計100時間ほど、データ量にして20TBもの走行データを集めています。日々データ量が増えていく中で、どれだけデータが膨大になってもML開発をスケールさせていけるように、ソフトウェアの観点から効率化をさせています。

画像提供:Turing株式会社
膨大なデータ量を踏まえたスケール前提のシステム開発
― 効率化とは具体的にどのような施策を行ったのですか?
主に3つの施策が挙げられます。
1つ目はバリデーターの自動化、2つ目にデータセット作成の高速化、3つ目にキュレーションプラットフォームの作成です。
― それぞれ聞かせてください。まずはバリデーターの自動化とは、どのようなことでしょうか?
これはデータの質の担保に役立つ施策で、アップロードされたデータに対して自動でバリデーションを実行し結果を検出するシステムをつくりました。インフラとしては、AWS Lambda上で動いていて、バリデーションのチェック項目は現在50〜60種類を挙げていますが、今後増えることも想定した設計にしています。
チェック項目のリストアップにはドメイン知識が豊富なエンジニアの知見を借りたり、社内で開催したバリデーション大会で出たポイントをソフトウェアに落とし込みました。
*バリデーション大会とは
チーム全員でデータのEDA(探索的データ分析)とバリデーションを行う社内イベント。見つけた不具合の数の多さを競う大会仕立てで、データ収集を開始した当初は月1回ほどの頻度で開催していた。

― 品質管理に全エンジニアが一丸となって取り組む姿はいいですね! 次にデータセット作成の高速化では何を行いましたか?
良質な学習データのみを凝縮したデータセットの作成において、自動化を行い処理スピードを向上させました。最初はエンジニアが手動で行なっていて、いくつもの工程があり、各処理には数時間から、長いものでは日を跨ぐほど時間がかかっていました。まだ一部手動処理は残ってはいますが、ほとんどが10分くらいで完了できるように効率化できました。
― 日を跨ぐほどの処理時間を10分に短縮するとは、かなりのインパクトですね!技術的にはどのような処理になっているのでしょうか?
自動運転用のデータは、動画や点群データのような非構造化データが中心です。そのため、たとえばSQLだけを使ってデータパイプラインを構築するといったことが難しいので、ETLをどのようなアーキテクチャで実現するのが最適か、悩ましいところでした。
今はデータパイプラインの多くはAWS Step Functionsを使って書かれており、その中から、AWS LabmdaやAWS Batchなどで実装されたExtract/Transform/Loadなどの処理を呼び出しています。非構造化データが対象とはいえ、データのExtractやLoadは比較的軽く並列化が容易なので、AWS LabmdaをDistributed Map上で動かすことが多いです。
ただ、ジョブによって依存するライブラリが違うことがあり、ジョブ毎に個別のコンテナイメージを用意していると、コードが分散しがちですし、テストも難しくなってしまうことが課題だと感じています。
― 開発をするにあたって、何か気を配ったことはありましたか?
僕が開発するものは、社内向けのSaaSみたいなものだと考えています。なのでバリデーターの自動化と同様に、今後データセットのサイズが増えたとしても問題なく動作するよう、拡張性には気をつけています。それからこのツールのユーザーにあたる、社内のMLエンジニアの要望を聞きながら、極力ユーザビリティを損なうことなく改善することも心がけています。
僕もAIのバックグラウンドがあり、やりたいことを理解しやすいので、そういう面でも貢献できていると感じています。

― では、キュレーションプラットフォームとはどのような取り組みなのでしょうか?
これは多様なデータセットを作るための、映像データを絞り込むプラットフォームです。例えば、右折と左折と直進、それぞれの走行シーンを1:1:1の割合で混ぜた学習データセットを作ろうとしたときに、それぞれ10個ずつ自動で選ばれてデータセットが即座に完成するといったものです。
技術選定に関しては、フィルタリングの項目やその組み合わせが多岐にわたることが想定されたため、データ分析に適したDWHを採用し、20秒毎の走行データに対して付けられたラベルを使って、所望のデータを検索できるようにしています。ラベル付けの機能については、AWS Fargateを使ったジョブキューを実装しており、ワーカーを増やすことで容易にスケール可能な設計にしています。
― このツールはみなさんの作業効率が上がりそうですね!
そうなんです。こういう社内ツールが自動運転のML開発を効率化させるから、ソフトウェア開発の視点が大切なんです。DWHを採用するにあたり、SQLを使ってクエリを書く機会が増えましたが、SQLを知らないエンジニアもいたので社内でSQL勉強会を開催しました。誰か1人ができるのではなく、チーム全員がデータベースを扱えることが大切ですから。
2025年の「Tokyo30」実現へ向けチーム全員で取り組む一体感

画像提供:Turing株式会社
― これまで成功例を伺いましたが、今直面している課題について教えてください。
僕たちは2025年末までに都内を30分間、人間の介入なしで運転する「Tokyo30」をマイルストーンに掲げています。その第一歩として今月末に、これまで開発してきた自動運転MLモデルを車に載せて走行させるのですが、全く動かないこともあるだろうと思っています。
画像情報の取得から制御の出力までの処理が遅ければ、連続走行は不可能だからです。なので、まずは処理スピードの向上が必須です。それから、走行させてみて課題を見つけ、設定したメトリクスに沿って一つずつ改善していきます。そのためのシナリオを作成し、リグレッションテストを含めて、人が介入しない時間を少しずつ長くしていくというのが、「Tokyo30」までの道のりです。
機械学習、ハードウェア、ソフトウェアのさまざまな分野から、この1つの課題に対してアプローチしていきます。
― さまざまな分野のプロフェッショナルが在籍していますが、働く環境としてはいかがですか?
自動運転実現の使命感を持ちつつも、アカデミックなチャレンジを含んだエンジニアリングを、みんなが純粋に楽しんでいるのがいいなと思っています。
先日はチームのみんなで走行テストフィールドに行って、実際にデータ収集車を運転し、誰が良質なデータを取れるか競う“データ収集大会”を開催しました。それぞれがこんなデータを取得したら、自動運転の精度向上に効きそうだという仮説を持って運転をしているんです。こうしたところでもチームの一体感を感じています。
広義でのソフトウェア開発の経験を積んだ人に来てほしい
― 最後に、関心を持っているソフトウェアエンジニアへ一言お願いします。
完全自動運転は自動車メーカー各社も取り組んでいますが、僕はソフトウェアエンジニアリングの延長線でつくった方が早いと思っています。なぜならソフトウェア開発の世界で再発見された、アジャイルやリーンといった開発効率向上の考え方が、自動運転MLモデルの実現にも役立つと考えているためです。当社はMLが強い会社ですが、そうした意味で広義のソフトウェア開発を学んだ人の力が必要なんです。
業務内容としても、MLモデルの規模が大きいので技術的なイシューが多岐にわたりますし、取得データ量が膨大で今後の持続性を考慮しなければならなかったりと、技術的な課題にやりがいがあります。
毎日20TBほど増え続けるデータをいかに扱うのかは、ビッグデータの分析基盤の開発運用の知識が必要になりますし、自動運転用のデータ基盤を整えていくことは他ではなかなか経験できないおもしろいフェーズです。関心がある方は、ぜひカジュアル面談でお話しましょう!