

2026年5月13日に開催されたオンラインイベント「Data Career Talk #1 事業成長を牽引する全社横断データ組織とは?」。Sansanとイオンスマートテクノロジーのデータエンジニアが登壇し、全社横断データ基盤を担う仕事のリアルを語りました。
Sansan株式会社の中村 崚さんは、技術本部 CTO室に所属するデータエンジニアです。「データに関して何でもやる」をモットーに、課題発掘からデータエンジニアリング、効果検証まで一気通貫で担う全社横断データ組織で、「Bill One」の事業成長とともにデータ基盤を育ててきました。
中村さんが振り返る3年間には、速度を優先して「先送りにした」判断と、それがフェーズの変化とともに課題に変わっていく過程が率直に描かれていました。本記事では、中村さんの講演をもとに、データ基盤のフェーズごとの意思決定とトレードオフの変遷をお伝えします。
中村 崚
Sansan株式会社 技術本部 CTO室
2023年4月にSansanにデータエンジニアとして参画。以降、全社横断データ基盤の開発からデータ利活用プロジェクトを推進。廃墟コードや多段スプシによるデータパイプラインと戦いつつ、直近ではAIエージェント開発なども手掛ける。 2025年11月に中部支店(@名古屋)に異動してからは、地方拠点の採用強化にもコミット中。趣味は山登りと名古屋のうまいもの巡り。
データ基盤がない状況。なぜ速度を最優先にしたのか
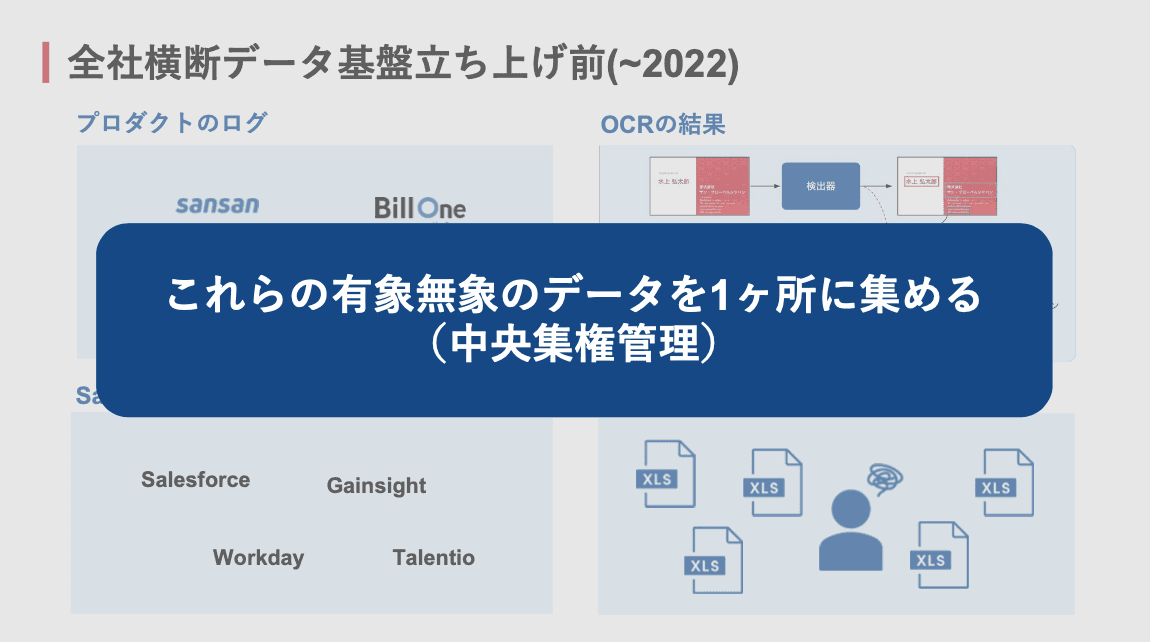
中村さんがSansanに入社する以前、社内のデータ環境はサイロ化していたといいます。プロダクトごとにAWS、GCP、Azureと異なるクラウド基盤を使い、データ基盤の技術スタックもまちまち。エンジニアが各基盤からデータを個別に抽出し、営業メンバーがスプレッドシート上で突合して手動でレポートを作成するという運用でした。
IMPORTRANGEやVLOOKUP関数でSFAと接続された「秘伝のスプシ」が何重にも連なり、1箇所が破綻すればすべてが崩れる多段構成。加えて、IaC化もされないまま放置されたGlue&Athenaの環境は、有識者がいなくなり、誰も全貌を把握できない状態になっていました。

出典:中村 崚|Bill Oneの事業成長とデータ組織のリアル
こうした混沌のなかで、Bill Oneをはじめとする複数プロダクトの事業拡大は加速していきます。MRRは年々増加し、契約者数も伸び続けて、組織の人員も増え、意思決定を高速に回すためのデータ基盤が不可欠になっていきました。中村さんによれば、横断データ基盤の構築は経営層レベルのオーダーとして降りてきたため、事業部やプロダクトのエンジニアも協力的だったそうです。
ただし、要件には大きな制約がありました。Sansanは名刺や請求書といった顧客情報を扱うため、セキュリティは最優先で守らなければならない。一方で、データを見るためにいちいち厳格な承認プロセスを踏む必要があると、利活用は進まない。セキュリティと利便性の両立が必須条件でした。
出典:中村 崚|Bill Oneの事業成長とデータ組織のリアル
2023年4月、GCP上にBigQueryを中心とした全社横断データ基盤がリリースされました。連携方式はオブジェクトベースのバッチ連携で、シンプルな実装を徹底。主要プロダクトのデータやSFAデータ、企業・人事マスタなどを搭載し、データセット単位でドメイン分割とアクセス権限を管理する構成としました。こうして全社横断データ基盤は立ち上がり、最初のデータ活用案件が動き始めます。
まず届ける。2つのデータ活用案件で正しく先送りにしたもの
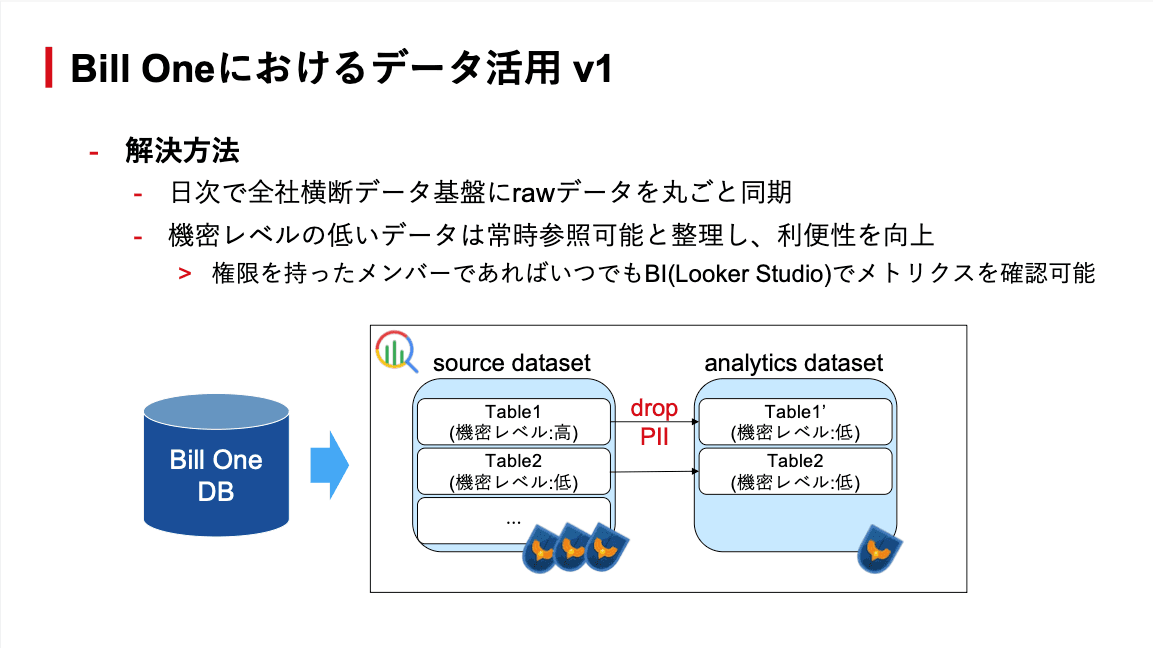
全社横断データ基盤の最初の案件は、Bill Oneの開発者向けでした。開発者がプロダクトの機能利用状況を把握するには、本番GCP環境にアクセスして本番DBにSQLを実行する必要がありました。DBへの過負荷の懸念があるうえ、データの機密レベルの高低にかかわらず、アクセスのたびに都度承認が求められる状況。中村さんはこの課題に対して、速度重視でシンプルな解決を選んだといいます。
日次でrawデータを全社横断データ基盤に丸ごと同期し、機密レベルの低いデータは常時参照可能に整理。source datasetとanalytics datasetに分離することで、機密性の高いデータはセキュリティを保ちつつ、低いデータは利便性を確保する構成としました。権限を持ったメンバーであればいつでもBI経由でメトリクスを確認でき、本番DBに負荷をかけずにrawデータへのSQL実行も可能に。横断データ基盤による価値提供の旗艦事例として、最速で提供されました。
ただし、中村さんはこのとき「先送りにしたこと」があったと語ります。データの加工処理はデータポータルのカスタムクエリで開発者が自由に実施する運用とし、基盤側では管理しない。また、開発者はデータの仕様やER構造を把握しているため、column descriptionなどのメタデータ付与は最低限にとどめる。いずれも、利用者がデータの中身を理解している開発者だったからこそ成り立つ判断でした。
出典:中村 崚|Bill Oneの事業成長とデータ組織のリアル
続く第二弾は、カスタマーサクセス(以下、CS)向けのデータ活用統一です。CSが顧客のBill One契約・利用状況をリアルタイムに把握できず、オンボーディングレポートの作成が人力かつ属人的になっているという課題がありました。たとえば、請求書受領の月間許容枚数に対して実際の利用が大幅に下回っていても、それをリアルタイムで把握できないなどです。
解決策として、全社横断データ基盤上でプロダクトデータとSFAデータをかけ合わせたマートを構築し、LookerでBIを提供しました。この段階でdbtを導入し、加工処理をマートに寄せる方針へ移行しています。社内500名以上の営業やPdMがLookerの数値をもとに意思決定できるようになり、CSもダッシュボードベースで顧客のリアルタイムの利用状況を把握可能になったといいます。
ここでも「先送りにしたこと」がありました。モデリングルールは厳密化せず、三層構造にする、PKにはジェネリックテストを付与するといったガイドライン止まり。SFAデータとプロダクトデータの読み解きは、横断データチームが気合で対応する運用でした。事業の成長スピードに合わせてデータ活用の価値を届けることを優先した結果であり、当時のフェーズでは合理的な判断だったと中村さんは振り返ります。
正しさの賞味期限。先送りが課題に変わるとき
開発者向け・CS向けの2つの案件を通じてデータ活用は社内に広がり、Bill Oneの事業そのものも拡大を続けていました。法人カードへの参入、経費精算機能の追加と、プロダクトの対象領域は次々に広がっていきます。サービスが増え、人が増え、データへの需要も増え続ける。2024年頃、先送りにしてきたものが横断データ基盤のペインとして表面化し始めたと中村さんは語ります。
中村さんは当時の状況を具体的なやりとりで振り返りました。「Bill Oneの決済データを参照したいけど、どのテーブルを見るべき?」と聞かれ、「◯◯テーブルです」と答える。すると「それどこでわかる?」と返ってくる。「ごめんなさい。メタデータ整備しきれてないです」開発者向けの案件で最低限にとどめたメタデータ付与が、そのまま課題になっていました。
もうひとつはプロダクトの方針変更への対応です。「機能追加と価格体系の変更があったので、利用状況を確認できるよう対応をお願いしたい」と依頼が来ても、SFAにどう登録され、プロダクトDBにはどう管理されているのかを読み解くのに時間がかかる。CS向けの案件でデータチームが気合で対応していたSFAとプロダクトデータの読み解きが、事業の拡大とともに追いつかなくなっていきました。モデリングルールをガイドライン止まりにしていたこともあり、データが増えるにつれ管理しきれなくなったといいます。

出典:中村 崚|Bill Oneの事業成長とデータ組織のリアル
こうした課題はBill Oneに限らず、他の事業でも顕在化してきました。負債が積もらないよう定期的な改善は続けてきたものの、事業が拡大するなかで大きな課題は避けられないものでした。
修繕ではなく、構造を変える
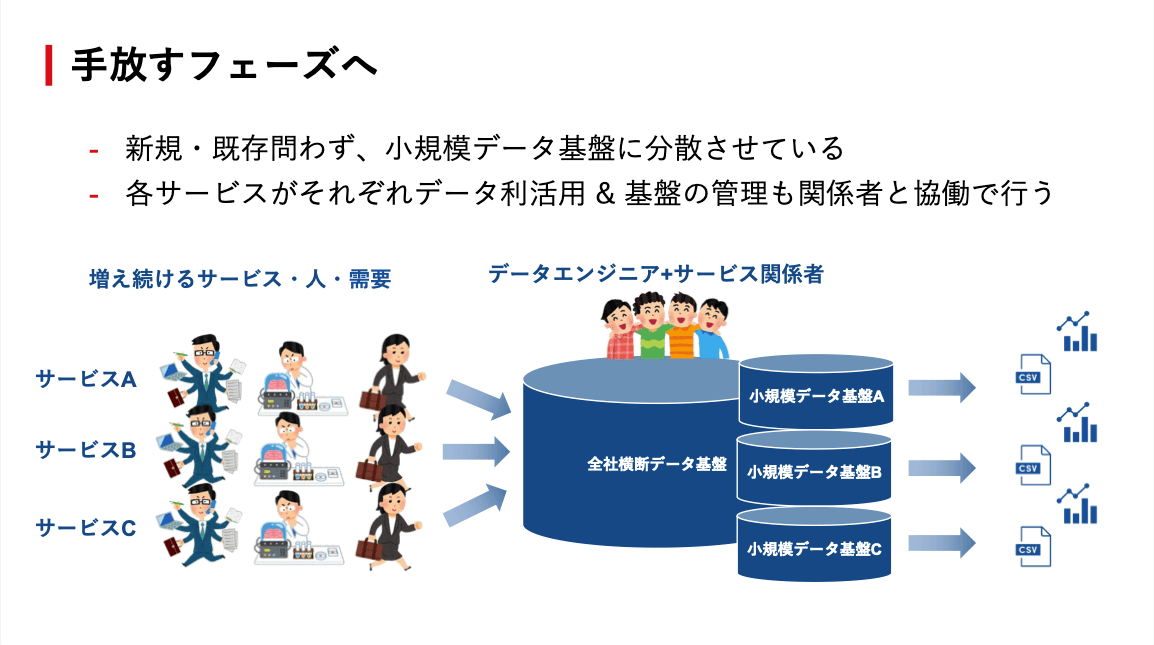
2026年現在、中村さんたちは「手放す」フェーズにシフトしています。新規・既存を問わず、サービスドメインごとに小規模なデータ基盤を配置し、各サービスの関係者がデータエンジニアと協働で利活用と管理を行う体制へ。横断で使うデータは引き続き全社横断データ組織がメンテナンスし、入り口は1箇所に絞ったうえで各基盤に配布する仕組みです。
出典:中村 崚|Bill Oneの事業成長とデータ組織のリアル
この方針に対して「それ、サイロに回帰していないか」という問いが当然出てきます。中村さんによれば、立ち上げ当初に1箇所に集めて利活用を始めたのは正当な意思決定でした。データ基盤がゼロの状態から、初手でデータメッシュやファブリックを志向するのはオーバーだったと考えられます。利活用が進み、運用する中でようやくペインが明らかになったのでした。
そのペインに対して選んだのが、型化した基盤(BigQuery、dbt、権限管理をワンセットにした実装)を各ドメインに配布するという方針です。技術スタックとガバナンスを標準化しながら分散させることで、中央集権に戻すのでも、野放しにするのでもないハイブリッド型を目指しています。3年間の運用で見えた課題を踏まえた構造の再設計でした。
講演のまとめとして、中村さんは「データ組織のフェーズによって取るべきトレードオフは常に変化する」「それゆえにデータ基盤は常に進化し、壊れ続けるものと捉えている」と伝えました。
| フェーズ | 重視すべきトレードオフ |
|---|---|
| 初期 | 提供速度 × セキュリティ |
| 拡大期 | データ品質 × スケーラビリティ |
加えて、CIやdbtテストが保証するのはあくまで実装の正しさであり、データ基盤のアーキテクチャや組織間のコミュニケーション設計まで含めた「合成物の整合性」は保証できない。つまり、技術だけでは解けない問題が残り続けるという認識です。
最後に、AI時代のデータエンジニア像についても中村さんは触れています。パイプラインを組むだけの狭義のデータエンジニアの仕事はAIに代替されうる。これからは、非構造化された散在情報を収集・統合し、データ基盤の一部としてチューニングしていく「噛み合わせる人材」がより重要になる。中村さんはそう見据えていました。
全社横断データ組織で働くことに関心のある方へ
本記事で描いたような「事業成長×データ基盤」の現場では、パイプラインの実装にとどまらず、事業部との伴走やアーキテクチャの意思決定まで幅広く担うデータエンジニアが求められています。
Sansanでは、本記事で紹介した全社横断データ基盤を担うデータエンジニアを採用中です。BigQueryやdbtを用いたデータモデリング、事業部と連携した課題発掘から効果検証までの一気通貫の業務に関心のある方は、ぜひご覧ください。中村さんが所属する中部支店でもエンジニア組織を拡大しており、地方からのリモート勤務にも対応しています。
まずは今の「やってみたい」を言葉にしてみませんか
「パイプライン実装の先にあるキャリアを考えたい」「全社横断のデータ組織でどんなスキルが求められるのか知りたい」と感じている方もいるかもしれません。Findyのコンサルタントとの面談は、自身のスキルや経験を整理するきっかけになります。
Findy会員様限定で、イベント本編をアーカイブにてご覧いただけます。動画やスライドと併せてお楽しみください。