

はじめに
データエンジニアとして日々の業務でデータパイプラインやデータマートを運用していると、「このデータの意味は?」「分析にはどのテーブルを使えばいい?」「同じような名前のカラムが複数あるが、違いは何?」といった問いに直面する場面は少なくないでしょう。組織が成長し、扱うデータが多様化・複雑化するにつれて、これらの問いに迅速かつ正確に答えることは困難になっていきます。
こうしたデータ探索における課題を解決し、組織全体のデータ活用能力を高めるために不可欠なのが「メタデータ管理」です。メタデータとは、一言で言えば「データのためのデータ」であり、データの意味、出所、形式、関係性などを記述した情報を指します。
本稿では、ある程度データ基盤の運用経験があるデータエンジニアの皆さんを対象に、組織の「知の巡り」をよくするためのメタデータ管理の実践的なアプローチを、具体的な事例やツールを交えながら深く掘り下げて紹介します。
なお、記事中では具体的なツールとしてBigQueryやdbtの名前が多く登場しますが、ここで紹介する基本的な考え方やアプローチは、特定の製品に依存するものではありません。例えば、本稿でBigQueryを例に挙げて説明していることはSnowflakeやDatabricksでも、dbtで紹介する手法はdataformなど他の変換ツールでも同様に実現可能です。皆さんの環境に合わせて、考え方を適用してみてください。
そもそもメタデータとは?
メタデータは、その性質によって大きく2つに分類できます。
- テクニカルメタデータ: システムが自動で生成・収集できる情報です。テーブルのスキーマ情報(カラム名、データ型)、更新日時、データ量、データリネージ(データの系譜)などが含まれます。
- ビジネスメタデータ: データのビジネス上の意味や文脈を記述する情報です。カラムの定義(例: 「売上」が税抜か税込か)、計算方法、利用上の注意点、担当部署など、人間が知識を付与する必要があります。
データ基盤の運用において、テクニカルメタデータは自動で収集されることが多いですが、本当に価値を発揮するのは、これにビジネスメタデータが組み合わさったときです。両者が揃って初めて、データはその真の意味を持ち、安全かつ効果的に活用できるようになるのです。
メタデータがないとどうなるか
もしメタデータが整備されていなければ、組織は「データのサイロ化」や「分析の非効率化」といった深刻な問題に直面します。
- データの探索コストの増大: 分析に必要なデータがどこにあるか分からず、探すだけで多大な時間がかかります。「"Order" という名前のテーブルが5つもあるが、自分が見たい月次売上の集計に使われているのは一体どれなんだ…?」といった事態は日常茶飯事になります。
- 誤ったデータ利用: アナリストがsalesカラムを使って重要な経営会議向けのレポートを作成したものの、後になってそのカラムが「テスト用のデータを含む、非公式な売上データ」であったことが発覚する。税抜と税込の定義を間違え、売上予測を大幅に誤る。このような事故は、ビジネスに直接的な損害を与えかねません。
- 属人化の進行: 「この複雑な顧客セグメントのロジックについては、3年前に退職したAさんのコードを解読するしかない」という状況が生まれます。その知識はドキュメント化されず、Aさんの頭の中にしか存在しなかったため、誰もその仕様に責任を持てず、改修もままなりません。
- データ品質への不信: 「このカラム、20%も欠損しているけどなぜ?」「このテーブル、先月から更新が止まっているのでは?」といった事象が頻発すると、データの定義や鮮度に対する信頼が揺らぎ、データ活用そのものが敬遠されるようになります。「この数字、本当に信じていいの?」という疑念が、データドリブンな文化の醸成を根本から阻害します。
このような問題の詳細な事例については、こちらの資料でも紹介しています。
メタデータの典型的な活用事例
これらの課題を解決するために、メタデータを整備することで実現できる具体的な活用事例を見ていきます。ここではいくつかの典型的な活用事例を、その効果と共に掘り下げて見ていきます。
データディスカバリーの促進
アナリストやビジネスサイドのメンバーといったデータ活用者は、そもそもどんなデータが存在し、それが何を意味するのかが分からなければ、データ活用の第一歩を踏み出せません。テーブルやカラムのdescription(説明)をビジネスメタデータとして整備し、それを検索・閲覧できるようにしたものが「データカタログ」です。データカタログがあれば、データ利用者はGoogle検索のように「売上データ」と入力するだけで関連テーブルを探し、その意味を正しく理解してセルフサービスで分析を進めることができます。これにより、データエンジニアは「このデータはどこにありますか?」といった基本的な問い合わせから解放され、より高度な業務に集中できます。
不要なテーブルの棚卸し
データ基盤が長期間運用されると、過去の分析で一度だけ使われたテーブルや、仕様変更で使われなくなったテーブルが増え、ストレージコストや、利用者の認知負荷(「このテーブルはまだ使っていいんだっけ?」という混乱)を増大させます。テーブルの参照ログ(テクニカルメタデータ)を分析することで、長期間誰にも使われていないテーブルを特定し、安全に削除することができます。ただし、直接参照されていなくても、そのテーブルを元に作られた別のテーブルが頻繁に使われているケースがあるため、データリネージを再帰的に辿り、末端の派生先まで含めて利用状況を判断することが不可欠です。具体的な実装例については、SQLを使った監視でデータ基盤の品質を向上させるでも解説しています。
データ品質の可視化と監視
データ品質は目に見えにくく、問題が発生してから気づくことが多いです。それでは手遅れになることもあります。メタデータはデータ品質を定量的に評価し、継続的に監視するための基盤となります。「このカラムはNULLを許容しない」「このカラムの値はA, B, Cのいずれかである」といった品質ルール(これもメタデータの一種です)をdbt testなどとして定義し、自動でチェックします。そのテスト結果(メタデータ)を集計・分析することで、「データセットごとの品質スコア」や「品質問題のトレンド」をダッシュボードで可視化し、プロアクティブな改善活動に繋げることができます。実際の可視化事例については、Elementaryを用いたデータ品質の可視化とデータ基盤の運用改善でも紹介しています。
Data Contractによる組織横断での仕様連携
データソース(例: アプリケーションDB)の仕様が、データ利用部門に知らされないまま変更され、下流のデータパイプラインが大規模に停止する、といった事故は、多くのデータエンジニアが頭を悩ませる問題です。近年注目されている「Data Contract」は、データの生産者(例: プロダクト開発チーム)と消費者(例: データチーム)の間で、データのスキーマ、品質基準、SLAなどに関する「契約」をメタデータとして明示的に定義するアプローチです。この「契約」に違反するような変更はCI/CDパイプラインでブロックされるため、予期せぬ障害を防ぎ、より堅牢なデータ基盤を構築することができます。実際の導入事例については、10XにおけるData Contractの導入についてでも解説しています。
メタデータ活用のためのツールと実践方法
メタデータの活用は、難易度に応じて段階的に進めることができます。ここではメタデータ活用の習熟度に応じて「初級編」「中級編」「上級編」の三つのステップに分けて、具体的なツールと実践方法を紹介します。
初級編: まずは、すでにあるメタデータを活用する
監査ログやINFORMATION_SCHEMAの活用
データウェアハウス(DWH)の監査ログやINFORMATION_SCHEMA(BigQueryの場合)は、宝の山です。どのテーブルが、いつ、誰に、どのくらい参照されたかという貴重なテクニカルメタデータが蓄積されています。これらを分析するだけでも、多くのインサイトが得られます。
例えば、BIツール(TableauやLooker Studioなど)がDWHに発行するクエリのログを分析すれば、「どのダッシュボードがどのテーブルを参照しているか」という関係性を明らかにできます。この情報は、テーブルの廃止を検討する際の影響調査や、障害発生時の影響範囲の特定に非常に役立ちます。
INFORMATION_SCHEMAを活用した具体的な分析手法については、データ管理に役立つメタデータに関する勉強会を社内外で開催しましたでも解説しています。
dbtを使っている場合、この関係性をexposureとして定義することで、データリネージにBIダッシュボードを含めることができます。
# models/exposures/tableau.yml
version: 2
exposures:
- name: sales_dashboard_jp
label: 日本市場向け売上ダッシュボード
type: dashboard
url: https://tableau.example.com/workbooks/12345
owner:
name: Sales Team
email: sales@example.com
depends_on:
- ref('fct_orders')
- ref('dim_customers')
しかし、ダッシュボードが作られるたびにこのYAMLファイルを手動で更新し続けるのは現実的ではありません。幸い、多くのBIツールはAPIや監査ログを提供しているため、そこから情報を取得してexposureのYAMLファイルを自動生成する仕組みを構築することが可能です。私も、TableauやConnected Sheets(Googleスプレッドシート)の情報を自動でexposure化する仕組みを構築・運用しています。
Tableauでの実装方法についてはこちら、Connected Sheetsでの実装についてはこちらをご覧ください。
中級編: ツールを導入して一歩進んだメタデータ管理へ
dbt-osmosisによるdescriptionの自動伝播
データマートをSQLを使って開発する際、カラムのdescriptionを記述するのは非常に重要ですが、同じ意味を持つカラムが下流の多くのモデルに登場するたびに同じ説明をコピー&ペーストするのは非効率で、メンテナンス漏れの原因にもなります。
dbt-osmosisは、この問題を解決してくれる強力なツールです。データソースに近いモデル(Stagingモデルなど)で一度descriptionを定義すれば、dbt-osmosisがデータリネージを解析し、そのカラムを参照している下流のモデルすべてにdescriptionを自動的に伝播・追記してくれます。これにより、最小限の労力でメタデータのカバレッジを劇的に向上させることができます。伝播させたdescriptionには、伝播元がどこかをコメントとして自動で付与することも可能で、メンテナンス性も確保できます。
データカタログの導入と実践
データディスカバリーを促進するデータカタログですが、その導入には注意が必要です。「最初から完璧を目指さない」ことが肝心です。多機能な商用製品を導入しても、その機能を使いこなせずに運用コストだけがかさんでしまったり、逆にフルスクラッチで自作しようとして開発・保守のコストで疲弊してしまっては本末転倒です。
データカタログの導入を検討している場合、まずはお使いのDWHに付属する機能から始めることをおすすめします。例えばGoogle CloudのDataplexは、特別な設定なしでBigQueryのテーブルやカラムを日本語で検索でき、運用負荷が低いのが魅力です。
より高度な機能(カラムレベルのリネージ、複数クラウドを横断した管理など)が必要になった段階で、OpenMetadataのようなOSSや商用製品を検討することをおすすめします。また、組織の成熟度やリソースに応じて、ZOZOの事例のように内製という選択肢もあります。小さく始めて、組織の成熟度に合わせてツールを育てていく視点が重要となります。
dbt-osmosisとDataplexを組み合わせた実践的な運用事例については、Dataplexとdbt-osmosisを活用した「がんばらない」データカタログとメタデータ管理の運用でも紹介しています。
elementaryによるデータ品質メタデータの収集と活用
elementaryは、dbtネイティブなデータ可観測性(Data Observability)ツールです。dbtの実行結果やテスト結果、manifest.jsonなどの成果物(artifacts)を自動で収集し、DWH内に正規化されたテーブルとして保存してくれます。
elementaryがこれらのメタデータをDWHのテーブルとして整理してくれることで、私たちはSQLを書くだけで以下のような高度な分析が可能になります。
- データ品質スコアの算出: データセットごと、タグごとなど、任意の粒度でテストの成功率を集計し、品質を定量化する
- テーブルの可用性モニタリング: モデルの実行失敗や遅延のトレンドを分析し、ボトルネックを特定する
- テストカバレッジの可視化: どのテーブルにどのようなテストが実装されているかを一覧化し、テストが手薄な領域を特定する
以下のSQLは、elementaryが作成したテーブルを使い、データセットごとのテスト実装状況(正確性の内訳)を可視化するクエリの一例です。このような分析を通じて、「このデータセットは一意性のテストが不足している」といった具体的な改善アクションに繋げることができます。
-- elementaryの成果物を使って、データセット毎の正確性テストのカバレッジを集計するクエリ
SELECT
models.schema_name AS dataset_name,
-- elementaryが付与する品質ディメンションで分類
tests.quality_dimension,
COUNT(tests.unique_id) AS number_of_tests
FROM
`my-project.my_elementary.dbt_tests` AS tests
JOIN
`my-project.my_elementary.dbt_models` AS models
ON tests.parent_model_unique_id = models.unique_id
WHERE
tests.quality_dimension IN ('completeness', 'uniqueness', 'consistency', 'validity')
GROUP BY
1, 2
ORDER BY
1, 2;
このクエリを使って作成したダッシュボードの例を以下に示します。
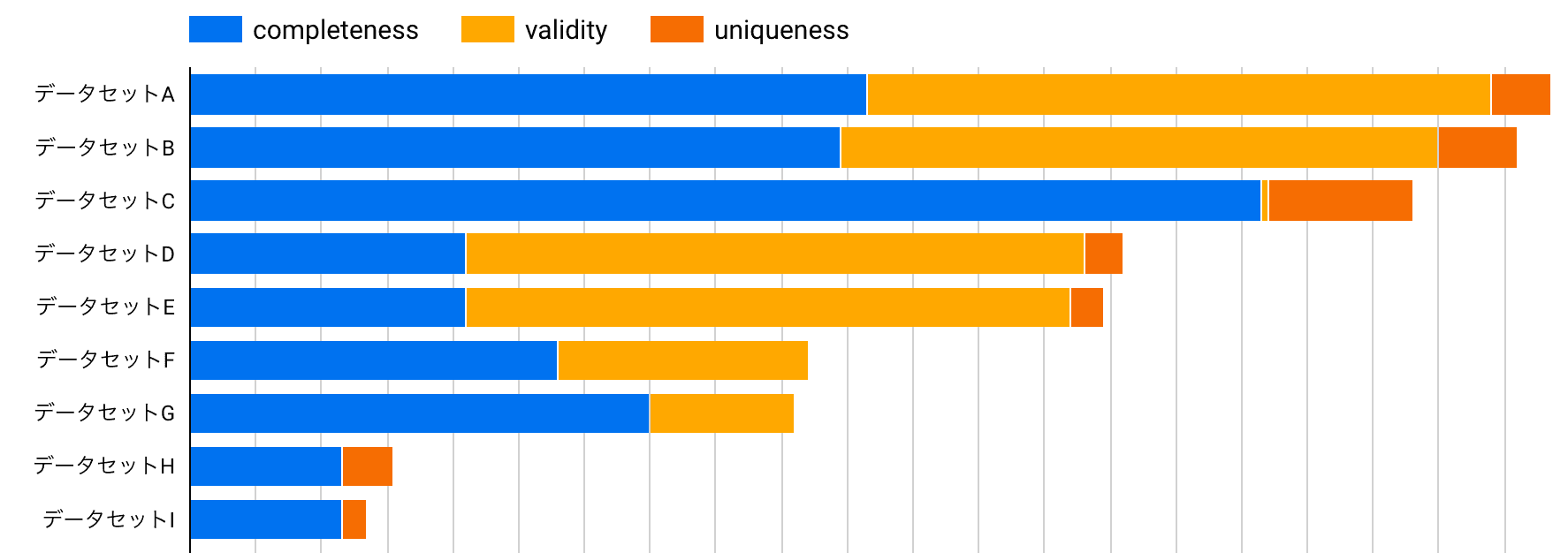
この可視化により、各データセットでどの品質ディメンション(完全性、一意性、一貫性、妥当性)のテストが実装されているかを一目で把握でき、テストが不足している領域を特定することができます。
詳細は以下をご覧ください: DWH改善に生かす! 入門elementary
dbterdによるER図の自動生成
dbtのリネージグラフはモデル間の依存関係を示しますが、「どのキーでJOINすべきか」というエンティティ間の関係性は示しません。この情報は、特に分析者が新しいドメインのデータを触る際に非常に重要です。
dbtのrelationshipsテストは、事実上の外部キー制約を定義していると見なせます。dbterdは、このrelationshipsテストのメタデータを読み取り、ER図(エンティティ関連図)をMermaid形式などで自動生成してくれるツールです。これにより、テーブル間の関係性を視覚的に把握でき、アナリストや他の開発者のデータ理解を大きく助けます。
# このrelationshipsテストがER図の「線」になる
models:
- name: fct_orders
columns:
- name: customer_id
tests:
- relationships:
to: ref('dim_customers')
field: customer_id
リポジトリ全体のER図を描画すると巨大になりすぎるため、中心となるテーブルを指定し、そこから数ホップの関係にあるテーブルのみを描画するなど、対象を絞る工夫をするとより見やすいER図になります。
実際にdbterdで生成したER図の例を以下に示します。
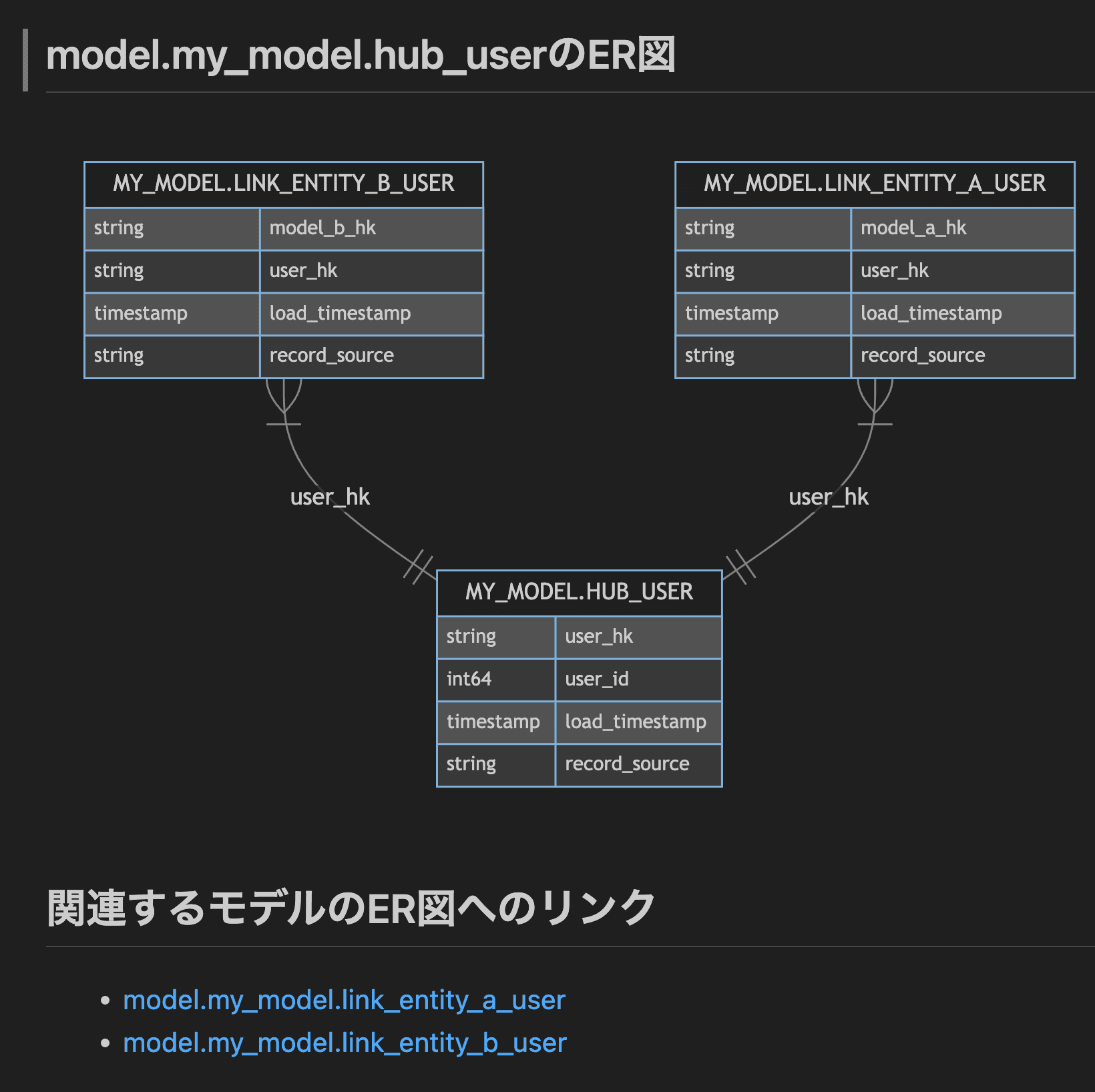
このように、テーブル間の関係性が視覚的に表現されることで、新しいドメインのデータを扱うアナリストでも、どのキーでJOINすべきかを直感的に理解することができます。
詳細は以下をご覧ください: dbtで見やすいER図を生成する
上級編: 組織を動かし、文化を育むための発展的アプローチ
ツールを導入するだけでは、メタデータ管理は完結しません。最終的には、それをどう組織に根付かせるかという、より組織的・文化的な側面が重要になります。
ビジネスメタデータの入力プラクティス:課題解決の三つの切り口
メタデータ活用の最大の壁は、「そもそも、入力されるべきビジネスメタデータが入力されていない」ことです。この課題に対し、すべてのメタデータを完璧に埋めようとすると挫折しがちです。そこで、組織の状況に応じて課題を解決するための、三つの切り口を紹介します。
1: カバレッジ効率を重視する メタデータ整備の初期段階で「とにかく全体的に情報が不足していて、どこから手をつけていいか分からない」という課題に直面することはよくあります。このような場合、ROI(投資対効果)を最大化するアプローチが有効です。具体的には、複数のデータマートから参照されている共通の上流テーブル(Stagingモデルなど)にターゲットを絞り、そこに集中的にメタデータを入力します。APIドキュメントなど定義が明確な情報から始め、dbt-osmosisのようなツールで下流のテーブルに自動伝播させることで、一つの上流テーブルへの労力が多くの下流テーブルに波及します。これにより、最小の労力で広範囲のメタデータカバレッジを効率的に向上させることができます。
2: ユーザーからの問い合わせを起点にする Slackなどで「このカラムはどういう意味ですか?」といった同じような質問が繰り返し発生している場合、それはメタデータが強く求められているサインです。このアプローチでは、頻繁に質問が飛び交うテーブルやカラムを優先ターゲットとします。問い合わせへの回答こそが、まさにユーザーが必要としているビジネスメタデータそのものです。
回答する際にその内容をdescriptionとして追記するフローを確立しましょう。このプロセスを通じて、システム移行の経緯や複雑なビジネスロジックといった、人の頭の中にしかない「暗黙知」を形式知化していくことができます。データ利用者が直面している問題を直接解決するため、メタデータ管理の価値を組織がすぐに実感でき、「分からないことがあれば、まずメタデータを見る」という文化の醸成にも繋がります。
3: ビジネスインパクトを重視する 経営指標(KPI)など、データの誤った解釈が大きなビジネスリスクに繋がるケースもあります。このアプローチでは、経営会議で使われるダッシュボードや、重要なKPIが含まれるテーブルを最優先で保護します。関係者へのヒアリングを通じて、データの定義や算出ロジックを正確にドキュメント化し、「この売上データは返品額を含んでいるため、純売上を計算する際は注意が必要だ」といった、利用上の注意点や陥りがちな「罠」を重点的に記述します。これにより、組織の最も重要な意思決定をデータの誤解から守り、信頼性の高いデータ活用基盤を築くことができます。
このアプローチにより、闇雲な努力を避け、本当に価値のあるメタデータの入力に注力することができます。詳しくは、ビジネスメタデータを入力するための私的プラクティスをご覧ください。
メタデータ管理を推進するための組織的アプローチ
優れたツールやプロセスも、それを使う文化がなければ形骸化します。メタデータ管理を成功させるには、技術的なアプローチと組織的なアプローチの両輪が不可欠です。
- 現状の可視化と優先順位の合意形成: もちろん、メタデータ管理自体はデータマネジメントにおいて重要な観点であることに変わりはありません。しかし、その取り組みを始める前に、まずは「データマネジメント成熟度アセスメント」(詳細はDMBOK参照)などを実施し、自分たちの組織がどのレベルにあり、本当の課題が何なのかを客観的に評価することが重要です。アセスメントの結果、組織のボトルネックが実はデータアーキテクチャやデータ品質そのものであると判明することもあります。メタデータ管理は万能薬ではないため、それが本当に今取り組むべき最優先課題なのかを客観的に判断し、経営層を含むステークホルダーと合意を形成することが、活動の成功に向けた第一歩となります。進めるべき順番や優先度を間違えないようにしましょう。
- 生産者責任の原則: データの生産者が、そのデータのメタデータにも責任を持つ、という文化を醸成することが理想です。「データを作った人がメタデータも書く」というシンプルなルールを徹底することで、情報の鮮度と正確性が保たれます。これは、データソースを開発するプロダクトチームと、データマートを開発するデータチームの双方に適用されるべき原則です。
- 文化の醸成: メタデータの間違いに気づいたら、誰でも気軽にプルリクエストを作成して修正する。問い合わせへの回答をきっかけにドキュメントを更新する。このように、メタデータ管理を「特別なイベント」ではなく、日々の業務に溶け込んだ自然な活動にしていく文化の醸成こそが、長期的な成功の鍵を握ります。
LLMとメタデータ管理
ここまでメタデータの重要性や、その入力、特にビジネスメタデータの整備がいかに大変かを述べてきました。これほど重要で大変な作業なのであれば、「LLMにSQLを読ませてdescriptionを自動生成させれば良いのでは?」と考えるのは自然な流れでしょう。確かにLLMは強力な助っ人ですが、過信は禁物です。LLMはコードの表面的な変換は理解できても、その背景にあるビジネスルールや歴史的経緯まで汲み取ることはできません。不正確なメタデータは、かえって利用者の混乱を招き、データへの信頼を損なう原因になります。
LLMは、複雑なSQLの読解補助や、メタデータの下書き作成、専門用語の確認といった「アシスタント」として活用するのが賢明です。最終的なメタデータの正確性に責任を持つのは、あくまで人間であるべきです。どうしてもLLMの生成結果を活用したい場合は、「この説明はLLMによって生成されました」といったタグを付け、人間による検証が済んでいないことを明記する運用が考えられます。
まとめ
本稿では、データエンジニアリングにおけるメタデータ管理の重要性から、その具体的な活用事例、そして実践的なツールや組織的なアプローチについて、難易度別に解説しました。
メタデータ管理は、一度やれば終わりというものではなく、データ基盤と共に継続的に育てていく活動です。最初はINFORMATION_SCHEMAの分析のような小さな一歩からでもかまいません。そこからelementaryやdbt-osmosisのようなツールを導入し、徐々に活動を広げていくことで、組織の「知の巡り」は着実に改善されていきます。
メタデータ管理は、時に地道な作業に思えるかもしれませんが、整備されたメタデータはデータに関わる全ての人々の生産性を向上させ、データドリブンな文化を醸成するための重要な土台となります。この記事が、皆さんのメタデータ管理の取り組みの参考になれば幸いです。
■査読:tvtg_24(@tvtg_24) / willanalysts(@willanalysts)