

本記事では、2025年5月14日に開催されたオンラインイベント「【技術選定を突き詰める】Online Conference 2025」内のセッション「技術の総合格闘技、生成AI時代のフルスタック開発」の内容をお届けします。同セッションでは、Admit AIのKenn Ejima(@kenn)さんに、生成AIの進化で予想される開発体制の変化を踏まえた上で、同氏が見いだしたシンプルなソフトウェアアーキテクチャや、その背景にある考えをお話しいただきました。ぜひ本編のアーカイブ動画とあわせてご覧ください。
Kenn Ejimaさん:まずは自己紹介をさせてください。Xのアカウント名は「Kenn Ejima」で、米国ではこの名前で活動しています。自身の肩書きについて明確に定義するのは難しいのですが、最近は「Full Stack Entrepreneur」と名乗っています。これはフルスタックの考え方を技術以外の分野にも拡張し、“会社を運営する上で必要なことは全て自分でやる”という姿勢を表しています。
6歳のとき、「ゲームを作りたい」という思いからプログラミングを始めました。それ以来、技術の探究を続けており、この世界ではもう長老の域に入っているかもしれません。大学卒業後は、日本で外資系企業やスタートアップを経験し、シリコンバレーではサービス開発に携わるほか、自らプロダクトを開発し、米国を中心とした北米市場向けに展開してきました。
その後、ニューヨークに移り、アジア系米国人向けのマッチングアプリ「EME(East Meet East)」を開発。当時はCTO 兼 Co-Founderとして、まさにフルスタックでプロダクト全体を作っていました。
帰国後は、英語圏で最大級のQ&Aプラットフォーム「Quora」の日本代表を務めました。2022年、ChatGPTが登場し、その圧倒的な進化を目の当たりにして「これは居ても立っても居られない」と感じ、再び起業を決意しました。
最初に手がけたのが、検索拡張生成(RAG)を活用し、社内データを含めたチャットボットの構築を支援する「Gista」です。現在は、米国の大学受験向けに、AIがエッセイの執筆などを支援するカウンセリングサービス「Admit AI」を開発・提供しています。従来は高額な費用がかかっていたオンラインカウンセリングを、AIが代替するというアプローチです。
こうしたプロダクトの開発を通じて、私が採用してきたソフトウェアアーキテクチャや、開発環境に対する考え方をご紹介します。
生成AIの登場で二極化するソフトウェアエンジニアの待遇
最近では生成AIがエンジニアに置き換わり、ソフトウェア開発者はいらなくなるのではないかという議論が出てきていますよね。シリコンバレーのソフトウェアエンジニアの年俸は上昇しており、中央値でも2000万円、上位10%になると5000万円を超える世界になっています。年俸1億円プレーヤーなどの人材も珍しくなくなり、夢のある職業になっている一方、生成AIの登場によってジュニアの入口はどんどん狭くなっており、二極化が進んでいます。
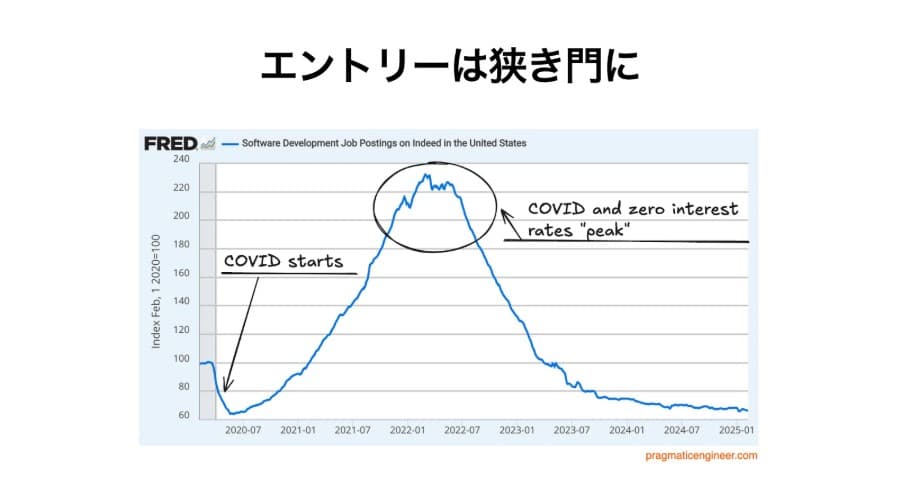
下図のグラフは、米国におけるソフトウェアエンジニアの求人数の推移を示しています。求人数がピークを迎えたのは、コロナ禍の時期でした。当時、米国政府が経済対策としてゼロ金利政策を実施した結果、企業は資金調達が容易になり、積極的に人材採用を行う動きが広がりました。しかし、社会経済活動が正常化するにつれて求人数は減少し、2025年現在ではコロナ禍初期の水準に戻っています。
AIの進化で予想される“少数精鋭化”と“内製化”
AIでソフトウェア開発が加速した未来には何が起きるのでしょうか。これは本当に大きな問いで誰も答えを持っていないと思いますが、私は仮説として“エンジニアの少数精鋭化&開発の内製化”という、一見矛盾している2つのことが同時に起きると考えています。
この仮説では、1人のエンジニアがDevinやCursor、Vercel v0など、さまざまなAIを使いこなすことで、これまでの10倍に及ぶパフォーマンスを発揮できるようになり、少ない人員で組織やプロダクトを運営できるようになります。同時に、現場で働く非エンジニアも自分たちが感じている課題を解決するため、AIの力を借りてソフトウェアを書くようになるでしょう。
技術スタックに対して、色眼鏡を外していく
フルスタック化には、“スタックの簡素化”を伴います。各スタックで本当に必要なものを突き詰めて考えることが、今後のトレンドになるのではないでしょうか。技術スタックの領域では、これまでの常識を疑うことが重要になります。さまざまなツールやインフラが整備されている企業で働いていると、“それがある/作るのが当たり前”という常識が刷り込まれているはずです。今後は、色眼鏡を一つ一つ外していくことが必要になるでしょう。例えば、フロント/バックエンドは本当に分離されているべきなのか、ステージング環境は本当に必要なのか、などを問い直すことは意味のあることだと思います。