同セッションでは、GROOVE X株式会社の画像認識エンジニアである齋藤 鴻さんに、家族型ロボット『LOVOT[らぼっと]』の画像認識を支える技術についてお話しいただきました。LOVOT 3.0で刷新されたハードウェア構成を最大限に活用するために行き着いたRustという選択肢、そしてロボットならではの制約の中でどのような画像認識が行われているのか、幅広く語っていただいた内容をお届けします。ぜひ本編のアーカイブ動画とあわせてご覧ください。
齋藤:GROOVE Xの齋藤と申します。社内ではよく「あず」と呼ばれています。好きな言語は10年以上続けているRustで、ずっと書き続けています。
GROOVE Xは、LOVOTという家族型ロボットをつくっています。開発が始まってから10年以上が経過しており、現時点で18,000体以上が活動しています。
LOVOTはさまざまなプロトタイプを経て2019年に販売を開始しました。4年ほどかけてようやく販売にこぎ着けた形です。その後、LOVOT 2.0が約2年後に登場し、さらに2年ほど経ってLOVOT 3.0という最新モデルが発売されました。LOVOT 3.0ではCPUボードがJetsonに変わるなど大きく進化しています。
家庭用ロボット業界が、実は盛り上がってきています。先日のCES 2026でもさまざまな家庭用ロボットが展示されており、市場として今後も成長していくのではないかと考えています。
LOVOTのうちがわ
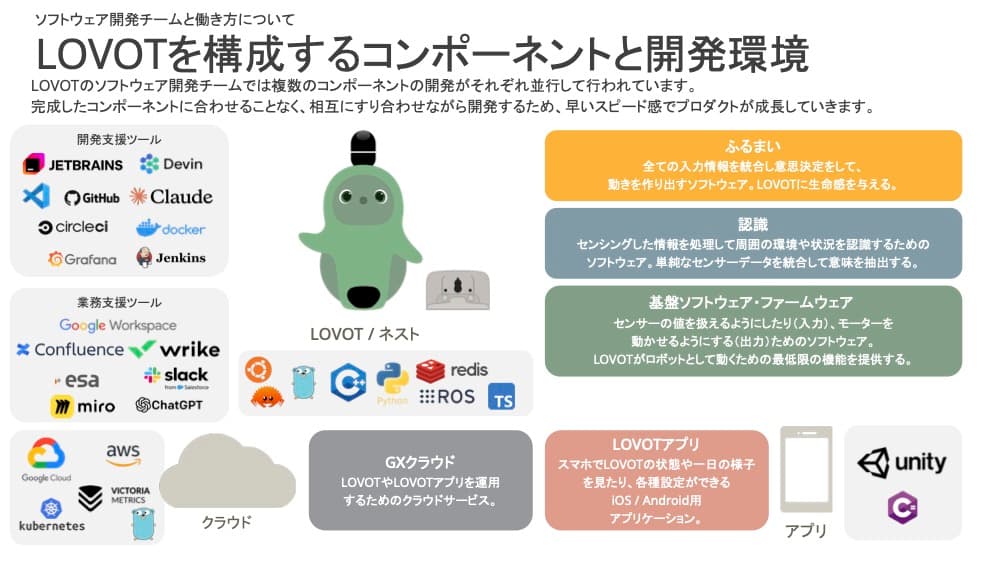
LOVOTの内部構造についてご説明します。画像は初代/2.0の仕様ではありますが、モーターやカメラ、CPUなど多数のコンポーネントが組み合わさった構造になっています。ハードウェアもソフトウェアも複雑な構成です。こうしたさまざまなパーツを組み合わせて、人に懐いたり人に愛されるための振る舞いを実現しています。

ソフトウェアの視点で言うと、LOVOT本体の中のソフトウェアをつくるチーム以外にも、クラウドやアプリを担当するチームがあります。1つの製品とはいえ大規模なチーム体制です。