

こんにちは、中田(@sanpo_shiho)といいます。とある海外のスタートアップで社内向けのPlatformの開発をしています(フルリモートなので日本在住です)。
2021年からKubernetesというオープンソースに貢献しており、現在はSIG-Schedulingのテックリードとチェアーを兼任しています。
今回の記事では技術的な内容を中心に、Kubernetes Schedulerとはなんぞやといったところから、現状の課題と発生している議論について深掘りしていけたらいいかなと思います。
その後、少し話をシフトし、Kubernetesのオープンソースの開発全般についてや、貢献をどのような部分から始めることができるかについて話していきます。
技術的な内容に関しては、できるだけ事前知識がなくても理解しやすいように説明していきますが、「PodやNodeとは何か」あたりの基本的なKubernetesの知識は前提とさせてください。
Kubernetes Schedulerとは
Kubernetes SchedulerはそれぞれのPodをどのNodeに配置するかを決定するコンポーネントです。Kubernetesを使用しているほとんどのユーザーが(その存在を認知せずとも)依存している重要なコンポーネントのうちのひとつと言えるでしょう。
KubernetesにはそのようなPodの配置に影響を与える複数の方法があります。例えば、
- NodeAffinity:このPodはこういったNodeに置きたい
- PodAffinity:このPodはこういったPodの近くに置きたい
- PodTopologySpread:これらのPod達はうまく散らして配置したい
- Taint/Toleration:このNodeにはPodをスケジュールしたくない。(明示的にPodがTolerationを付けることで例外的にそこにスケジュールすることができる)
などがあります。
また、Nodeのリソースの空き状況や、PodのImageのキャッシュをNodeが持っているかなどもPodの配置決定に影響しています。
Kubernetesにはスケジュールに関わる多くの要素があることがわかりました。Schedulerの内部的にはそれぞれの要素はプラグインという形で実装されています。上記で挙げた機能に対してNodeAffinity プラグイン、Inter-Pod Affinity プラグイン…などがそれぞれ存在するイメージです。
このPluggableなアーキテクチャはScheduling Frameworkと呼ばれ、KEP-624を通してv1.16で実装されました。
これはKubernetes Schedulerの拡張性に大きく寄与しており、例えば社内固有のスケジュール要件が存在する場合、独自のプラグインとして実装し、Scheduler内部で有効化することが可能になっています。
Scheduling Frameworkについてもう少し深掘りして、スケジューリングの概要を説明していきたいと思います。Scheduling Framework上ではプラグインが動作する**拡張点 (Extension points)**が定義されています。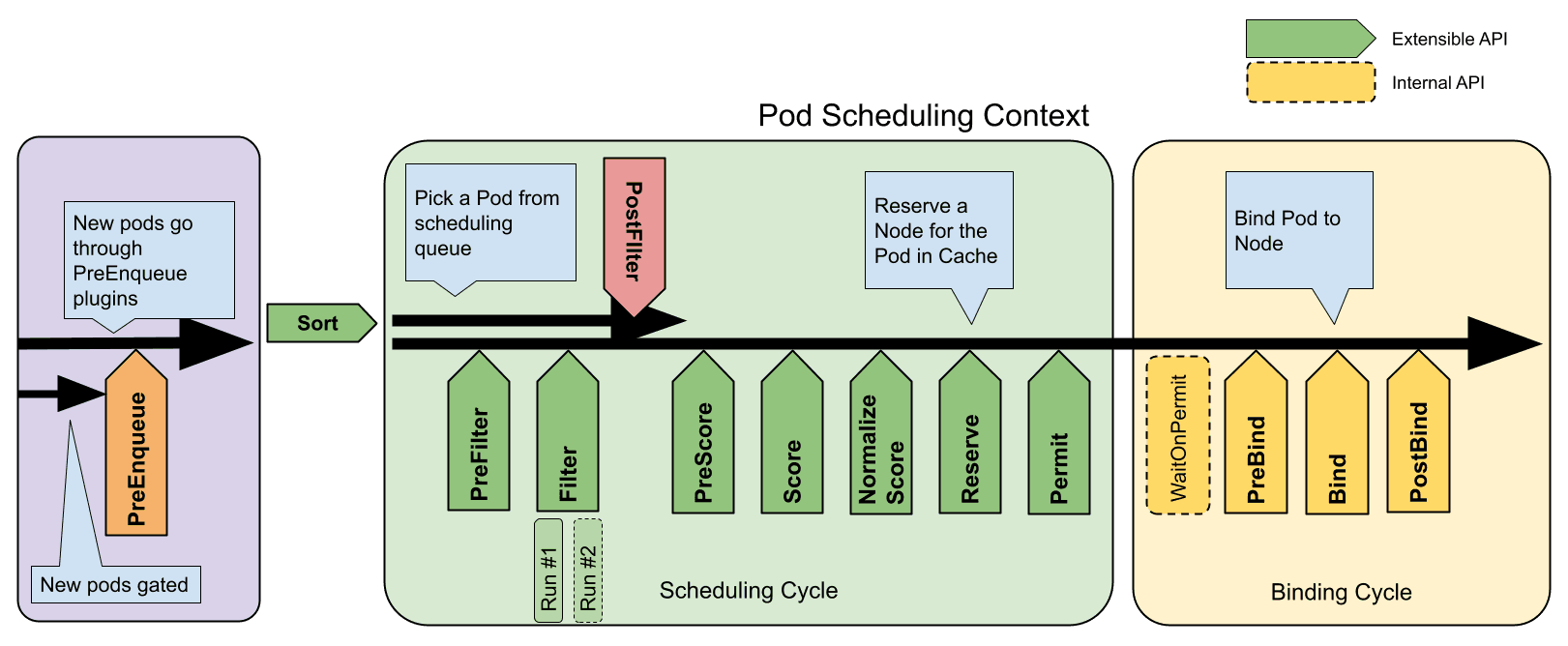
それぞれのプラグインは1つ以上の拡張点で動作するように実装されており、例えばNodeAffinity プラグインはPreFilter, Filter, PreScore, Scoreの4つの拡張点で動作することで、NodeAffinityという機能を実装しています。
そして、緑色に塗られたScheduling Cycleと黄色に塗られたBinding Cycleの2つが存在することに気がつくと思います。また、1番左の紫色の部分はScheduling Queueと呼ばれ、スケジューリング待ちのPodが溜まっています。
Scheduling CycleはPodをScheduling Queueから取り出し、一つひとつ処理していきます。その後、Binding Cycleが非同期的に実行され、Scheduling Cycleの決定に基づいてスケジュール結果を実際に適応します。
具体的にはPod内のNodeNameというフィールドに結果が入れられ、その後Kubeletがそれに気がつき、Podの実行準備に入るという流れとなります。
重要な拡張点である、FilterとScoreを理解するだけで、大体の流れを理解することができるようになります。
まず、FilterはPodがスケジュールされてはいけないNodeを候補から除外する拡張点となります。それぞれのプラグインがそれぞれのNodeを確認し、候補から除外するかどうかを決定します。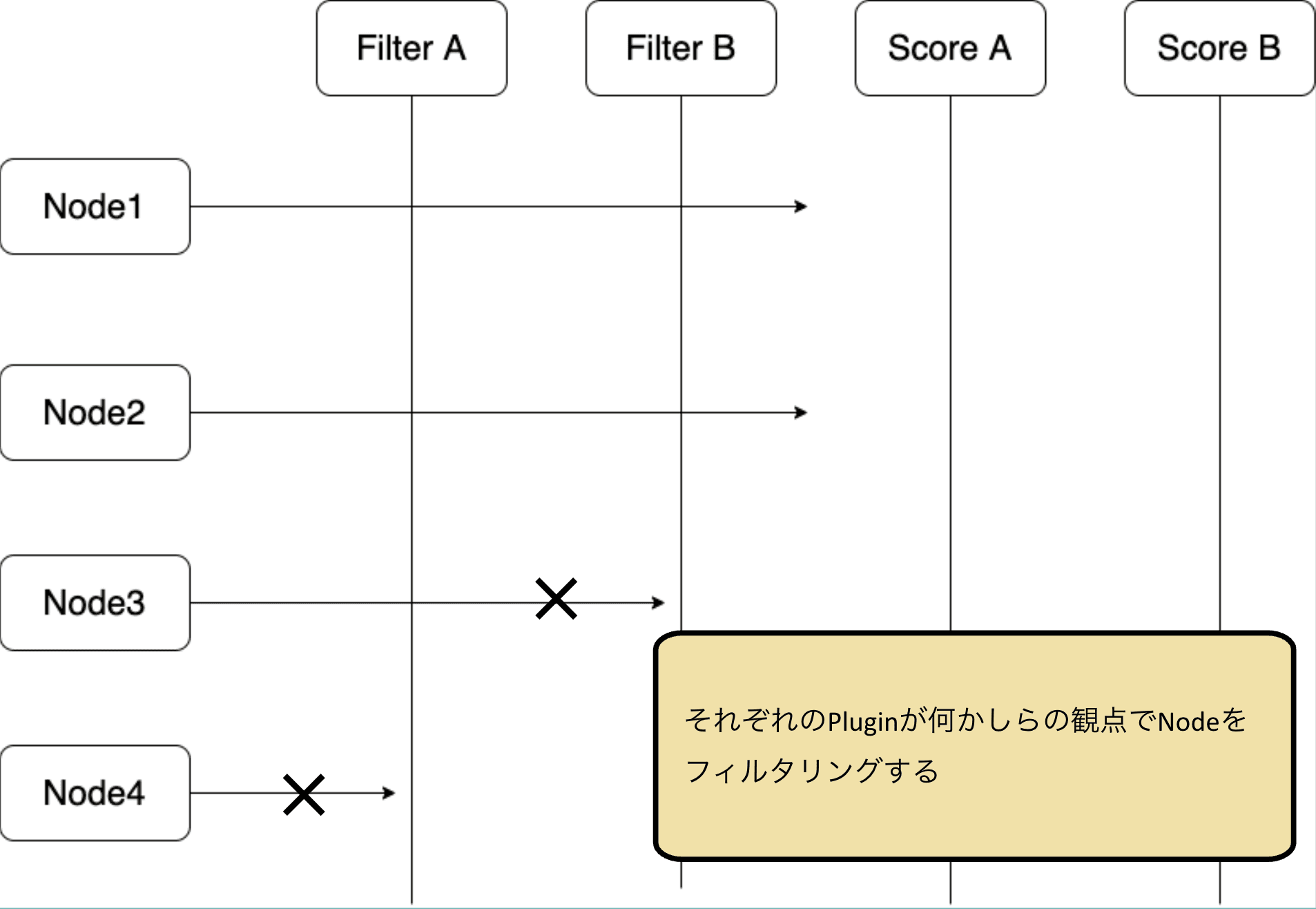
例えば、Podが要求するリソースを持っていないNodeなどはこの段階で除外されることになります。
すべてのプラグインを通り抜けたNodeのみが次のScore拡張点に進みます。もしくは、この時点ですべてのNodeが除外された場合は、PodはUnschedulableと判定され、Queueに戻されます。
Score拡張点ではそれぞれのプラグインがそれぞれのNodeを確認し、スコアリングを行います。
例えば、Podの使用するImageをNodeがキャッシュしている場合、そのNodeには高いスコアが与えられます。
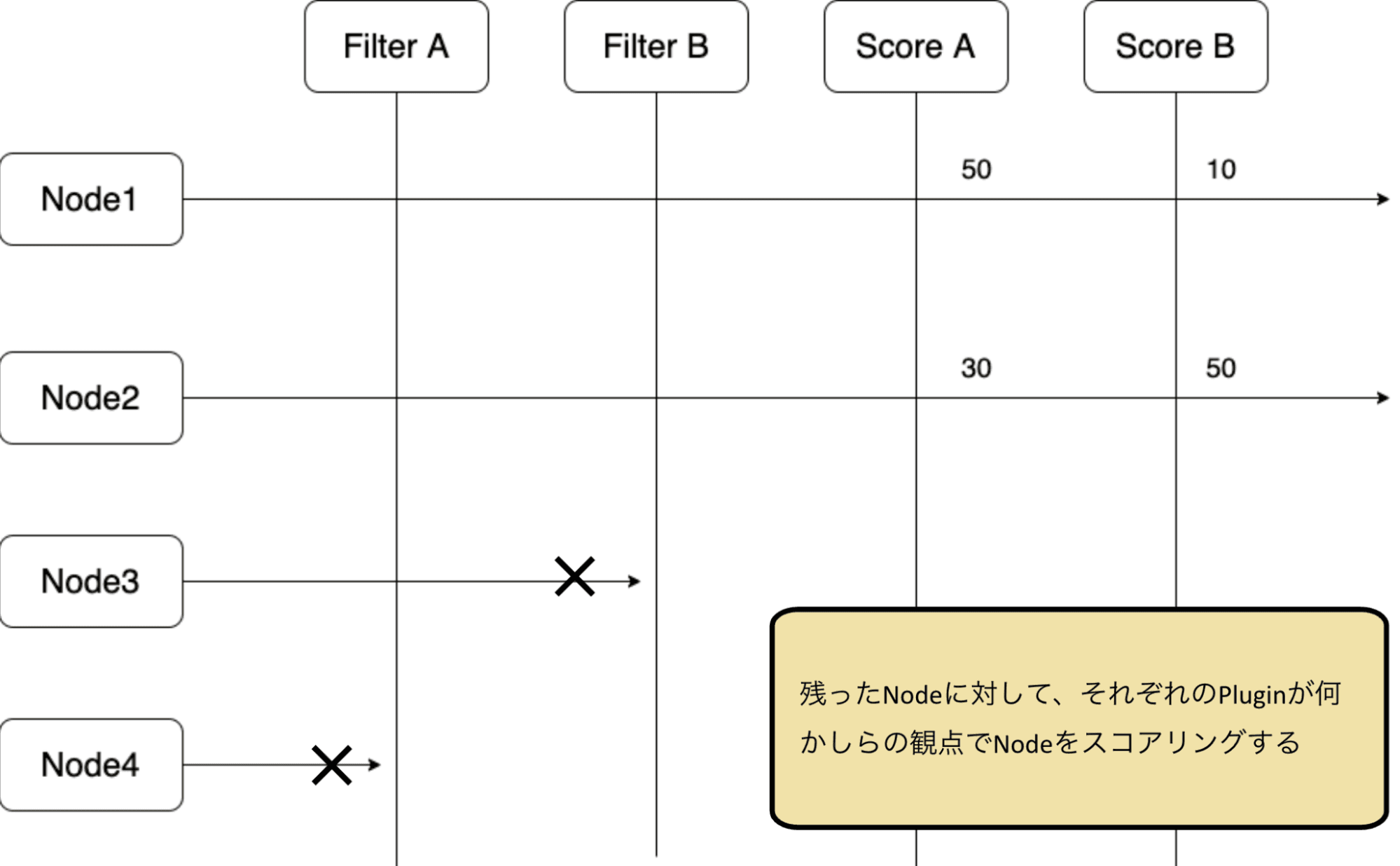
最終的にすべてのプラグインからのスコアを合計して最もスコアが高いNodeがPodのスケジュール先として選ばれます。
これで、FilterとScoreの拡張点がスケジューリングにおいて非常に大きな役割を担っていることが理解できたかと思います。
NodeAffinityなどの多くのスケジューリング制約は、RequiredもしくはPreferedとして指定することが出来るようになっていますね。そうです、ご想像の通り、Requiredとして指定した場合はFilter拡張点で、Preferedとして指定した場合はScore拡張点で処理されるように実装し、分けられているわけです。
図を見てわかるように、他にも説明していない多くの拡張点が存在し、それらの拡張点を組み合わせることで非常に多様なスケジュール要件の実装に対応することができるようになっています。
ここまでで、一旦Kubernetes Schedulerの基礎知識は身につけることができたと思います。
直近の動き - Performance matters!
最近のUpdateについて
ここまでで、Kubernetes Schedulerの仕組みについてざっくりと見ていきました。
ここからは直近のアップデートについて紹介していきたいと思います。
Scheduler、もといKubernetes全体として言えることではありますが、すでにユーザーが大量におり、それぞれの機能はかなり安定しています。
そのため、直近ではSIG-SchedulingはKubernetes Schedulerのパフォーマンス改善に力を入れていました。
(Dynamic Resource AllocationというKubernetes全体で取り組んでいる大きな機能もあるのですが、それひとつで大量に記事が書けるくらい濃い機能なので、この記事では紹介しません。)
Kubernetes Schedulerにおけるパフォーマンス、すなわちスケジューリングのスループットは他のコンポーネントと比較しても非常に大切です。
というのも、Kubernetesでは原則として「1つのクラスターに1つのスケジューラー」を推奨しています。そのため、クラスターが大きくなっても、スケジューラーの数を増やしてスループットを上げるということは不可能です。
理由としてはスケジューリング結果の競合があります。複数台のスケジューラーが仮に存在する時、それぞれのスケジューラーがPodの行き先を同時に決定する可能性があります。結果が競合すると、例えば1つのPodしか受け入れられないNodeに2つのPodが同時にスケジュールされてしまう可能性があります。
先ほど、Scheduling Frameworkの紹介の際、Scheduling CycleはPodを一つひとつ処理していき、Binding Cycleはその後非同期に実行されるということを紹介しましたが、これも同じような理由によるものです。
そして、スケジューラーがクラスターに1台しか存在しないと仮定すると、スケジューラーのスループットはクラスターのスケーラビリティに直結します。仮にクラスターが大きくなっていき、スケジューラーのスループットよりも新たなPodが作成されるスピードが上回ると、スケジュール待ちのPodがどんどんクラスターに溜まってしまうことになります。
Scheduling Frameworkの内、基本的にはPodを一つひとつ処理するScheduling Cycleのスループットがスケジューラー全体としてのスループットに直結してきます。私たちはそのパフォーマンス改善のために問題をいくつかに分類し、それぞれの改善を試みました。
- API呼び出し:Kube-apiserverへのリクエストとそのレスポンス待ちによるパフォーマンス劣化
- スケジューリングの再試行:スケジューリングの無駄な再試行によるScheduling Cycleの浪費
- Backoff time:無駄なBackoff待ち時間
API 呼び出し
まずは、1つ目API呼び出しについてです。先ほど紹介したように、Podのスケジューリング結果の適応のためのAPI呼び出しはBinding cycleという形で既に非同期になっています。
しかし、Scheduling cycleにはまだいくつかのAPI呼び出しが残っています。
- Schedulingが失敗した時にPodのConditionを更新するAPI呼び出し
- Schedulerが更新する`PodScheduled`と呼ばれるPodのConditionが存在します。
- Preemptionの際に既存のPodを削除するためのAPI呼び出し。そしてNominatedNodeNameを更新するためのAPI呼び出し
- Preemptionとは既存の優先度の低いPodを削除することで優先度の高いPodをスケジュールできるようにスペースを開ける処理のことです。SchedulerはNominatedNodeNameというフィールドにどこのNodeがPreemptionの対象となったのかを記録します。
- NominatedNodeNameとは「このPodがどのNodeへ行こうとしているか」を記録するPodのフィールドです。これにより、PreemptionをトリガーしたPodが次回のScheduling CycleでそのPreemptionが発生したNodeへ優先的に行けるように処理されています。
これらのAPI呼び出しの対策のために、まずはv1.32でAlpha、v1.33でBetaとなったAsynchronous Preemption(KEP-5229)という機能が存在します。
これは文字通り、Preemptionを非同期で行うための機能です。具体的にはPreemption内での既存Podの削除のAPI callを非同期で行うような変更になります。
スケジューリングの再試行
そして、次のスケジューリングの再試行に関してです。
スケジューリングが失敗した場合、どのようなタイミングでそのスケジューリングを再試行すれば良いと思いますか?Scheduling CycleがPodを一つひとつ処理していくものであることを考えると、Scheduling Cycleの無駄な試行はスループットの低下につながるため、適当にすべてのPendingなPodを再試行し続ければ良いわけではありません。
そこでスケジューラーは、クラスターの変化を監視することで、再試行のタイミングを決定しています。少しこの辺りの仕組みをご紹介します。
まず、Scheduling CycleのFilter拡張点がPodの可能な行き先を探しますが、そこで行き先が一つも見つからなかった場合、PodはUnschedulableという形でScheduling Queueに戻ってきます。その際に、「このPodはどのFilterプラグインのせいで戻ってきたか」をScheduling Queueは記憶します。%2520rejected%2520this%2520Pod..png&w=3840&q=75)
その情報に沿ってPodの再試行のタイミングが決定されることになります。
例えば、Node Resouce FitプラグインというNodeのリソース量の余りとPodリソース要求を比較し、リソースが足りないNodeを拒否するプラグインが存在します。仮に、Podのスケジューリングの際、すべてのNodeがこのプラグインに拒否されたとします。(つまり、すべてのNodeがリソース的に満員だったということですね)
そのPodは以下のいずれかが起こると、スケジュール可能になる可能性があります:
- 新しいNodeが作成された時
- 既存の実行中のPodが削除・スケールダウンされた時
- 既存のNodeが更新され、キャパシティが大きくなった時
Schedulerはクラスターの変化を監視し、上記のいずれかが発生すると「NodeResourceFitプラグインに拒否されたこのPodは今再施行すればスケジュール先が見つかるかもしれないな」という考えを元に再試行が行います。
Scheduling Frameworkには、そのように「どのようなクラスター上の変化が発生すれば、このプラグインに拒否されたPodを再施行すべきである」と指示するためのインターフェースがあります。
func (f \*NodeResourceFit) EventsToRegister(\_ context.Context) (\[\]fwk.ClusterEventWithHint, error) {
// Note: かなり簡略化しています。実際の実装が気になる方は以下です。
return \[\]fwk.ClusterEventWithHint{
{Event: fwk.ClusterEvent{Resource: fwk.Pod, ActionType: fwk.Delete | fwk.UpdatePodScaleDown}},
{Event: fwk.ClusterEvent{Resource: fwk.Node, ActionType: fwk.Add | fwk.UpdateNodeAllocatable}},
}, nil
}
このインターフェースを通してプラグインはリソースとそれに対する操作(作成、更新、削除 etc)を指定することができました。
ただ、例えばNodeResourceFitの例に戻ると、新しく作成されたNodeのキャパシティがPodよりも小さかった場合はどうでしょうか?その場合は、絶対にその新たなNodeにPodがスケジュールされることはあり得ませんね。
上記の仕組みではそのような細かい処理を行うことはできませんでした。つまり、新たに作成されたNodeがどんなに小さくても、NodeResourceFitに拒否されたPodはすべて再施行されていました。
そこでKEP-4247で提案され、実装されたのがQueueing Hintという仕組みになります。インターフェースの変更を見てもらった方がイメージがつきやすいかもしれません。
func (f \*NodeResourceFit) EventsToRegister(\_ context.Context) (\[\]fwk.ClusterEventWithHint, error) {
// Note: かなり簡略化しています。実際の実装が気になる方は以下です。
return \[\]fwk.ClusterEventWithHint{
{Event: fwk.ClusterEvent{Resource: fwk.Pod, ActionType: fwk.Delete | fwk.UpdatePodScaleDown, QueueingHintFn: f.isSchedulableAfterPodEvent}},
{Event: fwk.ClusterEvent{Resource: fwk.Node, ActionType: fwk.Add | fwk.UpdateNodeAllocatable, QueueingHintFn: f.isSchedulableAfterNodeEvent}},
}, nil
}
このようにそれぞれのイベントに対して`QueueingHintFn`という関数を渡せるようになりました。この関数はイベントの発生時に毎回呼び出され、プラグインはそのイベントでPodの再試行すべきかどうかを判断します。
これによって、クラスターの変化によってそれぞれのPodを再施行するかどうかの判断をより細かく行うことができるようになります。
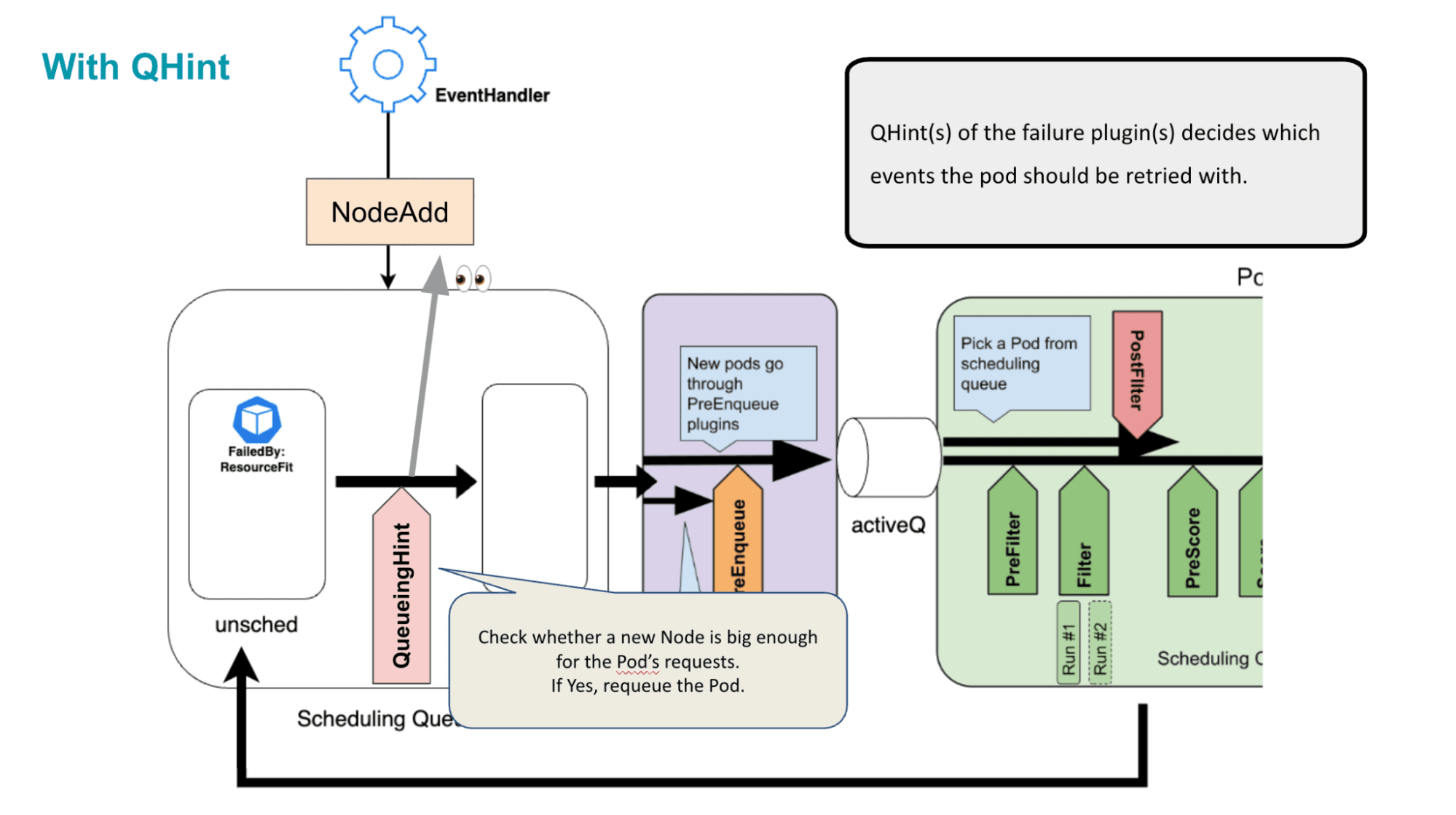
上記の例では、NodeResourceFitプラグインのNode/Createに登録されたQueueingHintは新たに作成されたNodeの大きさがPending Podに対して十分に大きいかを確認することで、Podのスケジューリング再思考の決断をより賢く行えることができるというわけです。
Backoff time
最後にBackoff timeについてです。PodはSchedulingに失敗するとScheduling Queueで計算された時間を過ごす必要があり、その時間がBackoff timeと呼ばれています。
例えばQueueing HintがPodがQueueに戻ってくるなりすぐにPodを再試行しようとしたとしても、必ず計算されたBackoff時間が経過するまで、Scheduling Cycleにすぐに戻ることはできません。
これはすべてのPodに公平にスケジューリングの機会を与えるためです。一部のPodが再試行され続け、その他のPodがScheduling Cycleに辿り着くのが遅くなるといった問題を防いでいます。
ただ、問題はすべてのQueue内のPodがBackoff経過待ちになっている時です。この時、Scheduling Cycleはやることが無く、いずれかのPodのBackoffが終了するのをただ待っている状態になります。
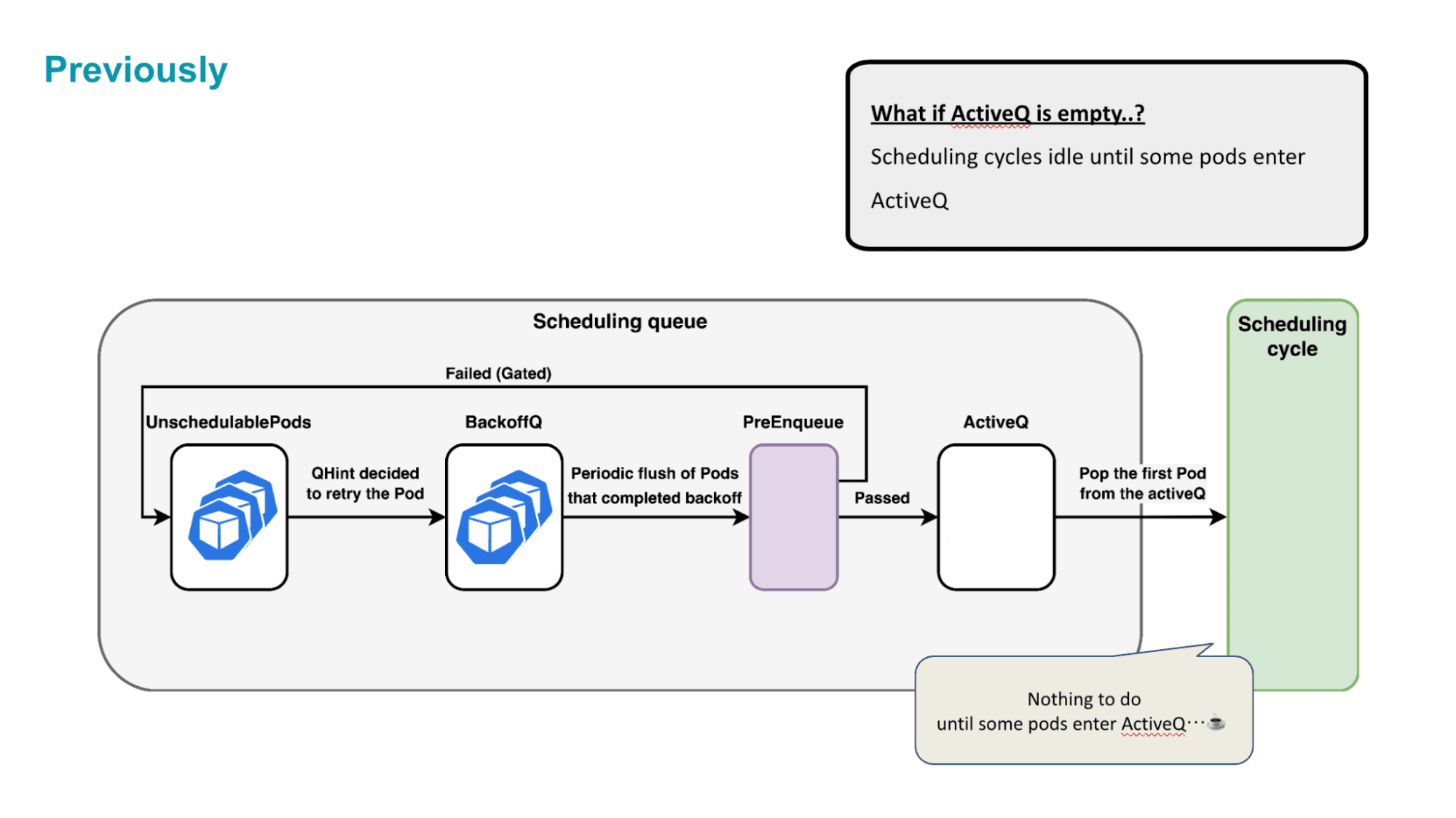
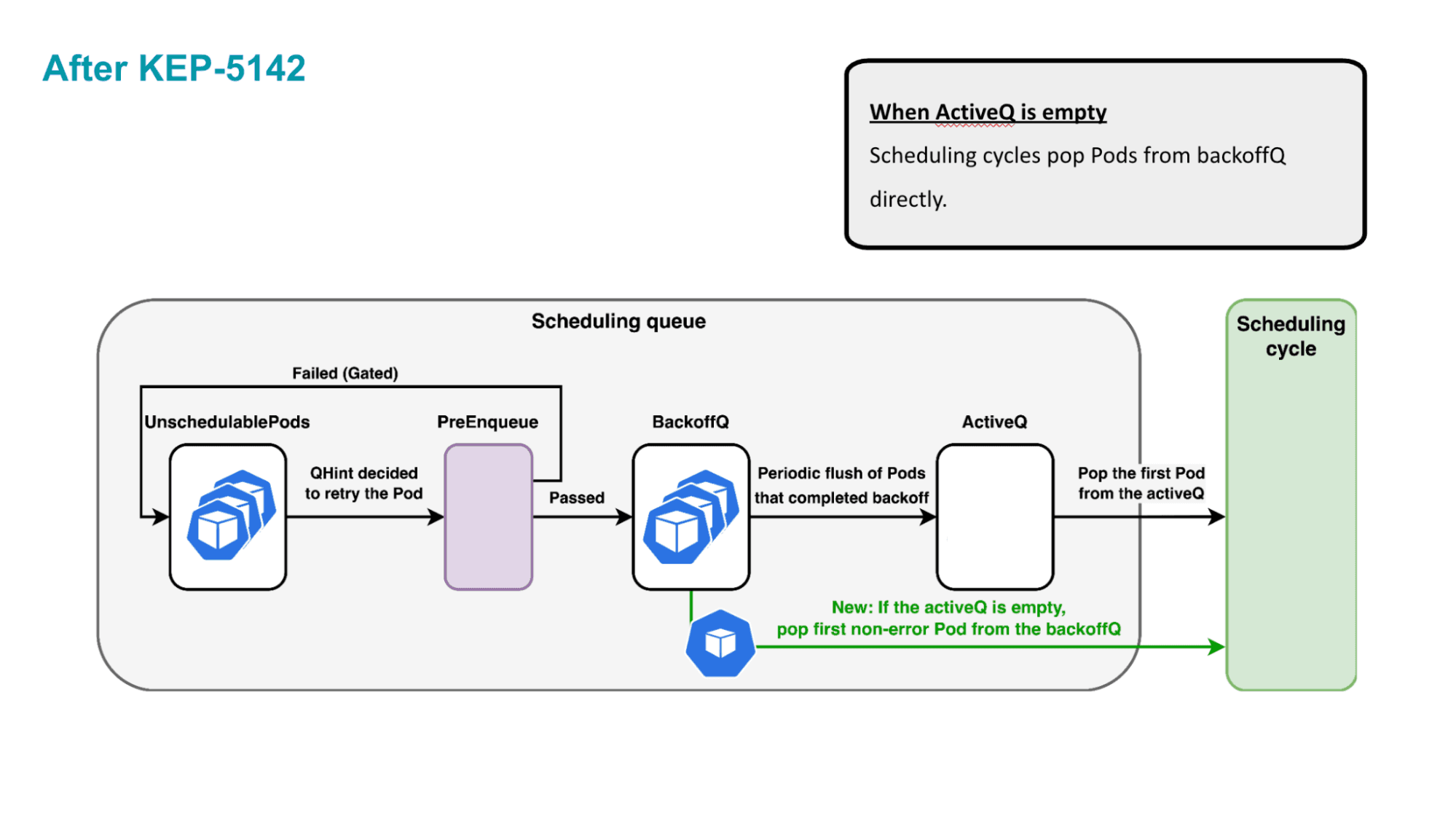
KEP-5142では、そのような場合にのみ例外的にPodはBackoffをスキップすることができるというような変更を加えました。
Kubernetes Schedulerのこの先
さて、ここまでで直近で実装された変更を紹介し、皆さんをKubernetes Schedulingの最前線までお連れしました。ここからは現在私たちが取り組んでいるもの、議論していることを紹介していきます。
Performance.. still matters!
まずは引き続きパフォーマンス改善のための変更です。
先ほどAPI呼び出しがパフォーマンス劣化の原因であること、そしてAsync Preemptionの機能を紹介しました。現在取り組んでいるKEP-5229ではすべてのAPI呼び出しをさらにまとめて非同期化する一般的な仕組みを作成しようとしています。
これにより、すべてのプラグインやScheduling FrameworkはScheduling Cycleをブロックすることなく、非同期にAPI呼び出しを行うことができるようになるはずです。
Nominated Node Nameの再考察
次に、NominatedNodeNameの再考察(KEP-5278)です。先ほどPreemptionの紹介の部分で、NominatedNodeNameについて軽く触れました。
現在はPreemptionでのみ使用されているのですが、幾つかの現存する問題と、機能要件を満たすために、再考察を行いました。
まず、外部のコンポーネントからのPodの行き先のヒントを受け取るためのNominatedNodeNameです。
例えば、Nodeを新たに作成するCluster Autoscaler、JobQueueingを実装しているKueueなどのコンポーネントは、内部でスケジューリングのシミュレーションを行っています。
- Cluster Autoscalerの場合、Nodeの作成時にPending Podを確認し、どのようなNodeを作成したらすべてのPending Podがスケジュールされるか、を計算した上で、Nodeの作成を行います。
- KueueはTopology Aware Schedulingという機能内で、どのようなPodの配置を行うことで、WorkloadのPodの最適な配置を行えるか、を計算し、PodのScheduling Gateを外しています。
つまり、これらのコンポーネントは内部で、「このPodはあのNodeにスケジュールされるだろう」といったようなある程度の目星がついています。これをNominatedNodeNameを通してSchedulerに伝えることができるようにしよう、という目論見です。
つまり、NominatedNodeNameはスケジューラーに対するヒントのような役割を持つことになります。NominatedNodeName付きのPodを受け取ったスケジューラーはまずそのNodeにPodをスケジュールできるかどうかを確認したのちに、ダメだった場合は別のNodeの確認に移ります。
また、NominatedNodeNameには場所の予約の意味合いも存在します。例えばKueueがPod1のNominatedNodeNameにNode1を入れたとします。この場合、高い優先度をもつPod以外は「そのNode1にはすでにPod1が存在する」という仮定のもとスケジューリングが行われます。これにより、Pod1が実際にScheduling Cycleにたどり着いた時にNode1に行くことができる可能性が高まります。
高い優先度のPodはその予約を無視して、Node1に行くことができますが、これは「Pod1がNode1上で動作していたらPreemptionによって削除された」と同様ケースとみなすことができるため、問題ではありません。
そして次に「SchedulerがPodの行き先が決定した際に外部のコンポーネントに伝えるためのNominatedNodeNameです。Dynamic resource allocationやVolumeの遅延割り当てが使用されている場合、Scheduling CycleでPodの行き先が決まったのちに、Binding CycleでデバイスやVolumeの処理が行われます。それらの処理は時間がかかる可能性があり、Binding Cycleが数分実行されているみたいなケースもあり得ます。
この場合、外部コンポーネントからはそのPodが単に場所を見つけられていないのか、もしくはBinding Cycleで時間がかかっているのかの区別がつきません。
これによって例えばCluster Autoscalerで実際に問題が起こっています。Cluster Autoscalerには空いているNodeを削除する機能がありますが、そのNodeが空いているのではなく、実際にはPodがそこに行く予定であるがBinding Cycleに時間がかかっているだけの可能性があるのです。長いBinding cycleでの処理を終えたPodがいざNodeへ行こうとすると、そのNodeがCluster Autoscalerにシャットダウンされてしまった、ということが現状あり得てしまいます。
これら、
1. 外部のコンポーネントからのPodの行き先のヒントを受け取る。
2. SchedulerがPodの行き先が決定した際に外部のコンポーネントに伝える。
の二つのユースケースに対応するために、NominatedNodeNameをPreemption専用のフィールドから、期待されるPodのスケジュール先を指定するフィールドへと一般化し、幾つかの実装の変更も行いました。
実は(1)の方に関しては、細かい実装変更のみで、大きな実装変更は行う必要がありませんでした。ただ、このようにKEPで明文化し、テストでもその挙動を保守できるようにすることで、外部のコンポーネントは安心してこの挙動に依存できるようになるわけですね。これはKubernetesレベルの大きなOSSならではな一面かもしれません。
Workload Aware Scheduling
現在SchedulerはPodを一つひとつ個別に扱いスケジュールを行なっています。ただ、時代とともにKubernetesのユースケースが増えていき、この方式だとうまく捌けないスケジュールのユースケースが増えてきました。そこで、複数のPodの集まりであるWorkloadを意識してSchedulingを行うWorkload Aware Schedulingが現在議論されています。(kubernetes issue #132192)
複数のPodを同時にScheduleすることを担保したいGang Schedulingや、Topologyを意識して最適な形で複数のPodを配置したいTopology Aware Schedulingなどが代表例です。
現状、それぞれには幾つかの解決策が乱立しており、これらの機能に依存したい外部のコンポーネントにとっては、選択肢になってしまっています。これをKubernetes本体でサポートすることで、すべてのコンポーネントで共通して使用できる標準機能として実装するのが目標になります。
ただ、言うは易しですが、技術難易度としてかなりレベルが高く、どのような構成にするのか、どのようにして現状のパフォーマンスを維持するのか、どのくらいの複雑さまでの機能を考慮するのか、など考慮する点が多くあります。現状まだKEPにもなっていない、議論の初期の初期の段階ではありますが、スケジューラー周りでは、ここ数年のうちの最も大きな機能になると思います。
終わりに
この記事ではスケジューラーの基本的な部分から、最新の機能、今まさに行われている議論までを紹介しました。
普段Kubernetesを触っていても意識しないスケジューラーの存在ですが、この記事が理解のきっかけになれれば幸いです。
この記事では技術的な内容にフォーカスして解説を行いました。
Kubernetesの開発やそこへの貢献といった、オープンソースとしてのKubernetesの紹介はまた別の記事で行おうと考えてます。