 シェア
シェア はてブ
はてブ
2024年6月28日、ファインディ株式会社が主催するイベント「開発生産性Conference 2024」が、開催されました。本記事では、株式会社スリーシェイク Sreake(スリーク)事業部のグループリーダー阿部 貴晶さんと、ソフトウェアエンジニア長谷川 広樹さんによるセッション「マイクロサービスの現場からプラットフォームエンジニアリングの可能性を探る!」の内容をお届けします。
セッション前半では、阿部さんからイベントテーマやタイトルのワードに関する意味や価値について、セッション後半では、長谷川さんから現場の課題に対してどのようにアプローチしているかについてお話いただいています。
■プロフィール
阿部 貴晶(あべ たかあき)
株式会社スリーシェイク Sreake事業部 グループリーダー
大学1年生の頃からMSPでアルバイトを開始して、インフラ運用監視の経験を積みつつ、24/365チームのマネジメントに触れる。 社会人になってからは同組織でインフラ構築・移設・二次障害対応に従事。 2020年5月から株式会社スリーシェイクに入社し、金融系のお客様を中心にインフラ周辺の実作業からコンサルティングまで幅広く対応。 現在は自社組織のリーダーをしつつ、エンプラ企業に対してSREやPlatform Engineeringの考えをどう活かすことができるか日々考えている。
長谷川 広樹(はせがわ ひろき)
株式会社スリーシェイク Sreake事業部 ソフトウェアエンジニア
データサイエンス分野 (R lang) で研究に取り組んだ後、Webアプリ (ドメイン駆動設計) のSWEとしてキャリアをスタート。 その後、スリーシェイクに入社。 現在はマイクロサービスアーキテクチャのインフラチームや、プロダクト横断のプラットフォームチームに参画中。 マイクロサービスアーキテクチャを支えるインフラ技術やドメイン駆動設計が好き。
事業インパクトにつながる開発生産性をどう捉えるか?
阿部:よろしくお願いします。ご紹介いただいた通り、「マイクロサービスの現場からプラットフォームエンジニアリングの可能性を探る!」というタイトルで、スリーシェイクの2名から発表させていただきます。私はSreakeという事業部でグループリーダーをしていて、普段はSREのプラクティス導入の手伝いをしたり、EKSを中心に据えた環境を横展開してデジタル決済を提供する案件に携わったりしています。
スリーシェイクは4つの事業を展開しており、我々はSREの考えをベースに技術支援を行うSreake事業部で、立ち上げ当初はインフラ領域を中心に、現在ではアプリケーションやセキュリティ領域も含め、全方位での技術的なご支援をさせていただいています。また、組織のコンサルティングなども行っています。
発表の構成として、前半は僕からイベントテーマやタイトルに入っているワードの意味や価値、つながりについて説明します。そして、後半は長谷川の方から、現場の課題に対してどのようなアプローチをとっているかについてお話しします。

阿部:今回、タイトルに「可能性を探る」と入れました。プラットフォームエンジニアリングには原則や性質や概要図が存在しますが、「これをやっておけばいい」という具体的な正解はなく、現場や開発者と向かい合ってつくり上げていくものだと認識しています。そのため、考えられる最も良いやり方を探すという意味で、「可能性を探る」と表現しました。
「開発生産性Conference」の公式サイトを見ると、昨年の開発生産性とは何かといったテーマから、今年は事業インパクトにつながる開発生産性や、具体的な生産性向上のための施策について踏み出すと書かれています。そこで、エンジニアとして事業インパクトにつながる開発生産性をどう捉えるか、というところから考えてみたいと思います。
Qiitaから引用させていただいた内容ですが、生産性をすごくシンプルに考えると、「生産性=アウトプット÷インプット」という式が一番しっくりくると僕は思っています。どのような値を入れるかは組織や立場によってさまざまですが、開発現場においては、できるだけ少ないインプット、つまり開発で発生するリソースやコストや時間をなるべく少なくして、アウトプットを増やしていくことを目指します。
開発生産性におけるアウトプットは、例えば、デリバリーの頻度などがあげられるでしょう。ただ、最終的にはアウトプットを増やすだけではなく、プロダクト利用者への価値や業績といったアウトカムを高めていく必要があります。
簡単な説明だったので、1つ資料を紹介させていただきますと、「開発生産性の現在地点~エンジニアリングが及ぼす多角的視点」という資料に、組織全体で開発生産性についてどう向き合うかといった話がまとめられていて、とても参考になります。
▶Qiita:開発生産性について議論する前に知っておきたいこと
https://qiita.com/hirokidaichi/items/53f0865398829bdebef1
▶開発生産性の現在地点~エンジニアリングが及ぼす多角的視点
https://speakerdeck.com/i35_267/current-status-of-development-productivity

阿部:では、どうやったらアウトカムが増えるのかを考えてみます。まず1つは、今あるプロダクトを素早くニーズに合わせていくために、市場が求めているものを目指すべく繰り返しリリースするには、デリバリーが高速だと嬉しい。もう1つは、市場が求めているであろう新しいプロダクトを素早く世に出していくために、新サービスを開発者への負担少なく、効率よく増やせると嬉しいということになります。
今あるプロダクトを素早くニーズに合わせると考えたとき、ニーズに合わせるための検証や改善、機能追加の場面で開発生産性、つまりデリバリーの速度や頻度を改善することで、PDCAを高速に回していくことが大事になります。
昨今、プロダクトマーケットフィットという言葉をよく目にします。顧客が求めている最低限のプロダクトを世に出し、それを使ってもらったうえで、価値の検証を通して改善や機能追加を行っていく。市場での検証を通して製品のニーズを把握し、マーケットにフィットさせていく考え方です。打席に立つ回数を増やすことでヒットを増やすようなイメージで、現場を確認しながら試行回数を増やすということですね。
もう1つ、新しいプロダクトを素早く世に出すことに関しては、昨今SaaSの企業ではマルチプロダクト戦略を取ることが増えていると思います。そうしたとき、開発現場では既存のプロダクトの知見を横展開したい。例えば、「あっちのチームがTerraformを使っているから、それを使うと環境が早くできるんじゃないか」とかですね。
そんなに簡単にはいかないものですが、素早く価値提供するためには知見を共有したり、なるべく車輪の再発明を避けて負荷となるインプットを減らしていきたいということになります。
また、コンパウンドスタートアップにおいて、複数プロダクトの素早いローンチや改善をするためにも開発生産性が重要だと言われています。なので、エンジニアとしては、開発生産性を上げることで、ビジネスサイドの人たちが考えてくれる施策を試行する回数を高め、ビジネスインパクトを大きくする確率を高めていくイメージで取り組んでいくのがいいと考えています。

認知負荷を削減するプラットフォームエンジニアリング
阿部:とはいえ、速度を出すのって難しいよねという話があります。昨今の課題として、開発者の認知負荷が挙げられます。僕たちがタイトルで言っているマイクロサービスであったり、それに使われるコンテナやオーケストレーションの概念、さらにはIaCでインフラを管理するといった話など、開発者の人たちが使うツールの量や考えの深さがどんどん増していって、開発者のメモリが足りなくなっている状態があると思います。
勉強したり調べたりするインプットは増加する一方で、アウトプットする機会がどんどん減少してしまって、デリバリー頻度の減少に繋がってしまう。そうすると確率も下がってしまい、アウトカムも出しづらくなり、負のサイクルに陥ってしまいます。
こうした認知負荷を削減したい状況のなかで、プラットフォームエンジニアリングの注目度が高まっています。プラットフォームエンジニアリングについておさらいすると、今このクラウドネイティブと言われている時代で、ソフトウェアのエンジニアリング組織において、セルフサービス機能を実現するツールチェーンや、開発のプロセスを一気通貫で実現するワークフローの設計や構築をしたりする学問と言われています。
アプリケーションのライフサイクル全体、開発からリリース、その後の運用まで行っていくなかで、必要なものをカバーするInternal Developer Platformというプラットフォームを、社内の開発者向けにプロダクトとして提供していく考え方です。
そのプラットフォームエンジニアリングには、特性とされているものがいくつかあります。こちらはCNCFのホワイトペーパーから持ってきたものですが、後半で発表する内容に合うように、この中から少しピックアップして紹介したいと思います。

阿部:まずは、「Platform as a Product」。プラットフォームをプロダクトとして捉えましょうというものです。プラットフォームは、ユーザーの要求に応えるために存在しています。なので、「これがあった方がいいかもしれない」ではダメで、開発者が何を求めているのか、生の声をしっかり聞くコミュニケーションが重要だと思っています。
また、プラットフォームを使うチームがどんどん増えていくなかで、単一のチームからの「これを実装してほしい」という要望に応え続けるのではなく、みんなが求めている一般的なユースケースをサポートする機能を提供していく必要があります。横断的に標準化を進めてプラットフォームを作り上げていくイメージで、このことはplatformengineering.orgというサイトでも大事な原則として挙げられています。
そして、接着剤となりツールチェーンをまとめ上げ、ワークフローを提供することには価値があると言われています。これも結局は、システムだけでなく人々の間を取り持つことが重要なので、そういうコミュニケーションにしっかりと時間を割いていくことも重要だと僕は考えています。

阿部:次は「Documentation and onboarding」で、プラットフォームなので利用するための文書や例をちゃんとつくっていきましょうという話です。オンボーディングが楽になるように、コードやテンプレート、ドキュメントなどがしっかりまとまっていると嬉しい。そして、利用者の知見や体験が均一化されると、例えば悩みもだんだん近づいてきたりして、無駄やコミュニケーションが減り、生産性の向上が期待できると自分は考えています。
まとまって提供されると嬉しいものとして、ゴールデンパスと呼ばれる考えがありますが、例えばスケルトンのソースコード、インフラで言うとCI/CDのパイプラインやIaCのコード、Terraformで言えばモジュール、Kubernetesで言えばHelmチャートの例など、開発で使うであろうセットをしっかり開発者にまとめて提供します。

阿部:あとは、「Optional and Composable」で、機能を選択して利用できると嬉しいという話ですね。必要に応じて独自の機能を使いたいし、それをカスタマイズできると嬉しいので、そうやってつくっていきましょうということです。
それから、プラットフォームエンジニアリングの成熟度についても触れたいと思います。すごく重要だと思うのが、どの項目も成熟度が上がるにつれて、資金や人が要する時間に対する要求が大きくなる点に注意が必要だということです。
こうした成熟度モデルの、OPTIMIZINGという最高レベルの目標を見ながらやっていくと進まないので、最高レベルに達すること自体を目標にせず、自組織や現状が恩恵を受けられるかどうかをしっかり検討していく必要があります。
なので、この成熟度モデルに、今自分たちの組織がどの状態にいるのかをマッピングして、それを四半期や半年、1年ごとに反復し、そのなかで改善のために次に取り組むべきことを検討していくことが大事だと思っています。

マイクロサービスのメリットと現場で向き合うべき課題
阿部:大きな単語が飛び交っているので、ここでイメージを整理します。最終的に、利用者への価値となるアウトカムを届けていきたい、ビジネスインパクトを起こしたいと考えるなかで、やはりユーザーや社会が大事になってきます。
それに対して、ビジネスサイドの人たちは市場調査をしたり、事前に出したプロダクトのフィードバックから、自分たちがどういう価値提供をしていきたいか考えたりしてくれています。そして、それをどうやったら叶えられるか、こういうものがつくりたいといった話が開発者との間で生まれます。
そうして開発者たちが受け取ったとき、昨今の開発環境で何かをつくろうとすると、例えばCI/CDをどうするか、オブザーバビリティのツールをどうするか、ドキュメントもつくらなければいけないし、インフラのコードも書かなければいけない。ワークロードやセキュリティはどうするか……といった話がすごく大きくなってきているので、それをプラットフォームとして開発者に提供していきたいということですね。
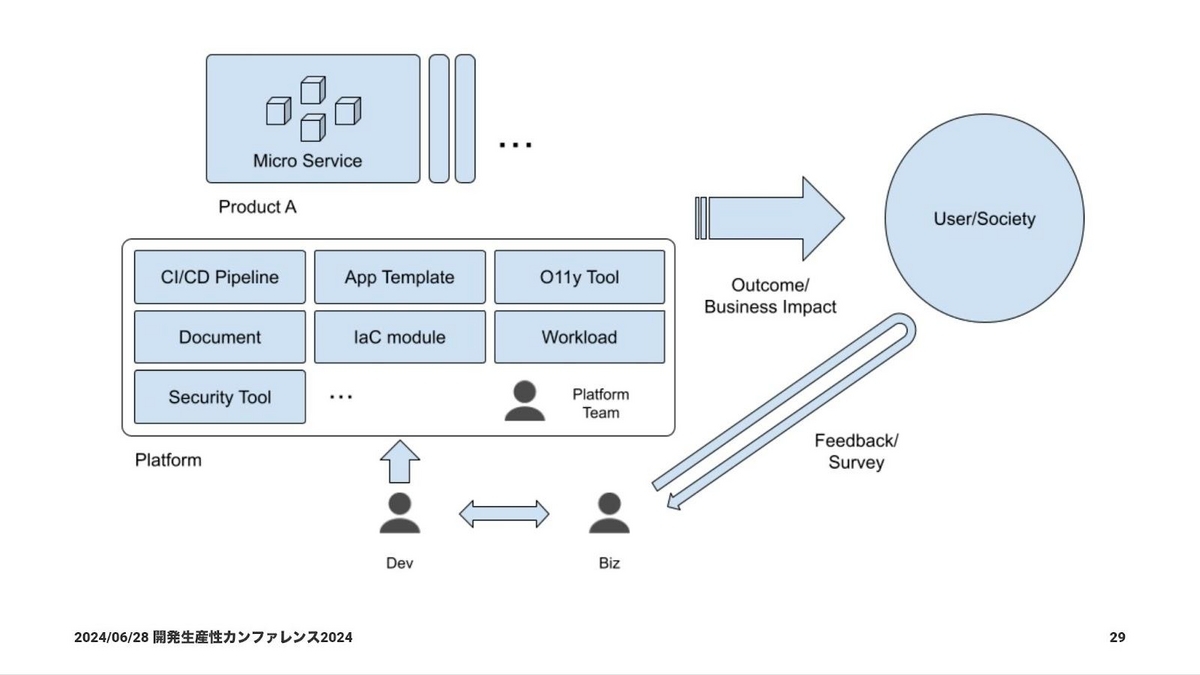
阿部:ここからはマイクロサービスの現場において、インフラ面からそれをどう最適にできるかについて話していきたいと思います。マイクロサービスのメリットはこのように挙げられますが、そのなかで今回はデプロイの容易性と、組織との連携について触れていきます。
メリットを見ると、マイクロサービスが良さそうだと飛びつきたくなりますが、やはり難しいことも多く、開発生産性に影響あるものがたくさんあります。例えば、大量のトランザクションが発生しているなかで、どこかで失敗してしまったとき、サービスごとのトランザクションをどう担保するのかとか。開発者体験が悪くなったり、遅延の場所を探すのが難しくなったりなど、さまざまな問題が発生してきます。

阿部:マイクロサービスの特徴の1つとして、デプロイの容易性があります。個々のサービスが独立することによってデプロイの自由度が上がり、迅速なデプロイやロールバックが可能になる。それによって顧客への価値提供が素早くでき、仮説検証をループするスピードが上がります。
ですが、開発者からすると、認知負荷がものすごく上がってしまうという問題があります。リリースの方法は複雑になるし、設計も難しくなる。テストを異なるサービス間でどうするかという問題が出てきたり、レビューが複雑になったりします。あとは、新しい技術を導入するにあたって、理解するための労力が増すという問題もあります。
また、マイクロサービスと組織に関しては、複数のプロダクトないしサービス間で、独自で開発できるようになるというメリットがあります。その反面、組織間の知見の共有が難しくなり、車輪の再発明が起きてしまう可能性がある。なので、情報共有や吸い上げをする役割、仕組みがあると嬉しいということになります。
このようにステークホルダーが多くなるため、コミュニケーションコストは増大します。コミュニケーションは大事だと言いつつ、プラットフォーム側でできるだけ吸収できた方がいいということですね。
では、前半のまとめです。開発生産性を上げることで、ビジネスインパクトを大きくする確率を高めていきたい。そのためには、デリバリーの速度を上げて検証のサイクルを速めたり、車輪の再発明を防いだりといったことが必要で、そうした意識が小さなインプットで大きなアウトプット、そしてアウトカムを生み出すために重要だと思っています。
ただ、デリバリーの速度を落とす要因として、昨今高まっている認知負荷があり、それを解消する観点でプラットフォームエンジニアリングが盛り上がっています。そうしたなか、定義や原則の考えをしっかりと用いて現場の課題と向き合っていくことが重要で、その結果として開発生産性を高めるプラットフォームをつくり上げていきたいと考えています。
それでは、後半に続きます。なお、株式会社スリーシェイクでは、絶賛仲間を募集しております。興味がある方は、ぜひこちらのサイトにアクセスしてもらえると嬉しいです。

プラットフォームエンジニアリングで生産性を支える取り組み
長谷川:後半は「マルチプロダクトの巨大組織で、マイクロサービス開発を支えるCI/CDプラットフォーム設計」というテーマで発表させていただきます。長谷川広樹です、よろしくお願いします。マイクロサービスアーキテクチャのインフラ領域をメインに仕事をしていて、少しだけアプリもやっています。サービスメッシュのIstioが好きです。
今回は、プラットフォームエンジニアリングで生産性を支える取り組みについてお話します。まずは、私がどのような組織でエンジニアリングしているかを紹介しようと思います。

長谷川:現在、規模の大きなIT企業のフィンテック部門でエンジニアリングをしています。図のように、プロダクトチームがA、B、Xと複数あり、それぞれが独立したフィンテック系のプロダクトをつくっています。そして、プロダクトチームの開発を支えるプラットフォームチームがあり、私はプラットフォームチームとプロダクトチームの2つに所属しています。
プロダクトチームの中には、マイクロサービスの開発チームとインフラ全般を開発するSREチームがあります。プラットフォームチームは、各プロダクトチームに伴走しながら、アプリとインフラの両面でいろいろな取り組みをしています。具体例としては、CI/CDの標準化や分散トレースのパッケージの標準化などですね。今回は、CI/CDの取り組みをご紹介します。

長谷川:マルチプロダクトの巨大な組織には生産性に関する、とある課題があります。この図は、プロダクトチーム間のコミュニケーションに関するつらみを表したものですが、プロダクトチーム間は基本的にあまり交流がなく、コミュニケーションに溝があるんですね。そのため、プロダクトチーム間で共有されない知見がたくさんあります。
例えば、プロダクトチームAで何かしらの知見が生まれても、それがBに共有されることがあまりない。そうすると、「同じものをつくっていました」という車輪の再発明が次々に起こります。これでは、組織全体の生産性が良いとは言えません。

長谷川:また、マイクロサービスアーキテクチャでも生産性の課題があります。我々はマイクロサービスごとにリポジトリを分割する、ポリレポという戦略を採用していて、この図ではそのポリレポ戦略のつらみを表しています。
アプリの実装で、ドメインロジックが同じになることは基本的にないと思いますが、マニフェストやHelmチャートといったものは、マイクロサービスごとに同じような構成になります。そうすると、各マイクロサービスの開発者は、レビューがだいたい同じになってくるんですね。
例えば、Helmチャートの構造が正しいか、マニフェストの文法が正しいか、ベストプラクティスに違反していないかなど。これはプロダクトチームとして、あまり生産性が良くないなと私は思います。

横断的なコミュニケーションで課題解決にアプローチ
長谷川:続いて、まずはコミュニケーションからのアプローチで、どのように課題を解決していったかを紹介しようと思います。プラットフォームの設計導入のために、ステークホルダーを巻き込んでいくという話ですね。
この図は、私が実践した組織内での振る舞いを表しています。プラットフォームエンジニアリングではステークホルダーがたくさんいて、各プロダクトチームは基本的にあまり交流がなく、それぞれに開発のリーダーがいます。
そういう人たちとコミュニケーションをとって巻き込んでいかないと、やはり良いプラットフォームは設計できません。私は幸いにも、プラットフォームチームとSREチームの両方に所属しているため、行き来しやすい状況にありました。

長谷川:この図の①「CI/CDの課題を吸い上げる」では、私がプラットフォームチームとプロダクトチームを行き来して、プロダクトチームが抱えているCI/CDの課題をヒアリングしました。
次の②「課題を解決できるCI/CDプラットフォームを設計」では、ヒアリングした内容をもとに、実際にプラットフォームを設計しました。のちのち他チームにも提供していくことになるので、ここではプロダクトチームXだけに対応した方法ではなく、拡張性が高い方法で設計していくことが必要になります。
③「CI/CDの導入方法を設計」では、導入に際してできるだけ作業負荷にならないように、プロダクトチームの開発サイクルなどを考慮して、より簡単にCI/CDのプラットフォームを導入できる方法を調査しました。
④「プロダクトメンバーを巻き込んでCI/CDを導入」は、実際にプロダクトチームの人たちに、我々がつくったものを使ってもらうところです。コミュニケーションをとり、伴走しながら行いました。先ほどお伝えした通り、ポリレポはリポジトリがたくさんあるので、プロダクトチームの上の方とコミュニケーションをとって、みんなで協力してやってもらうことが必要でした。
続いて、⑤「他プラットフォームメンバーを巻き込んでCI/CDを導入」です。先ほどいろいろなプロダクトチームに提供していくという話をしましたが、私は他のプロダクトチームとの交流がありませんでした。そこで、他のプロダクトチームと交流のあるプラットフォームのメンバーを巻き込んで、一緒に協力しながら導入していきました。
最後は、⑥「機能改善の窓口となる」ですね。実際に導入してみると、「こういう機能を使いたい」といった要望が結構上がってきます。そうしたときに、私が窓口となって機能追加などに対応していきました。このような形で、さまざまなコミュニケーションをとりながら進めてきました。
横断的なCI/CDパイプラインの提供により生産性を支える
長谷川:次に、どのような技術で課題を解決したかを紹介しようと思います。この図が採用しているCI/CDパイプラインの全体像で、CI/CDパイプラインの種類が3つあります。
1つ目がアプリのCIパイプラインで、2つ目がKubernetesのマニフェストやHelmチャートのCIパイプライン。そして、最後にCDパイプラインがあります。今回は、真ん中のCIパイプラインとCDパイプラインのところをご紹介します。

長谷川:真ん中のCIパイプラインは、リポジトリのプッシュから始まって、最後は開発者の承認までいきます。CDパイプラインの方は、ステージング環境へのマイクロサービスのデプロイから始まって、本番へのデプロイで終わるという形ですね。まずは、真ん中のKubernetesリポジトリのCIパイプラインの詳細をご紹介しようと思います。
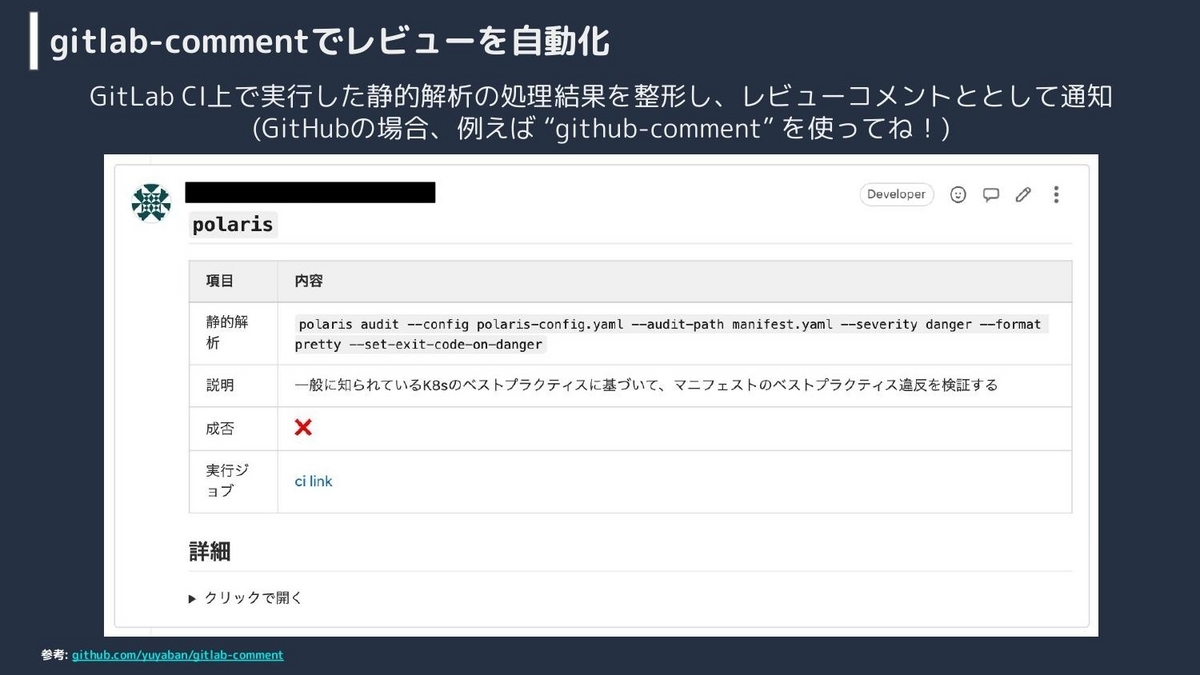
CIパイプラインの各ステップの設計を簡単に図にしました。最初に、gitlab-commentというツールを使っています。これはGitLabのマージリクエスト、GitHubで言うプルリクエストですが、そこにレビューコメントを送信するツールですね。これをインストールしています。
そして、Helm lintコマンドを実行したり、Helm templateコマンドを実行したりして、最後にいろいろなテストを実行しています。例えば、図のPolarisのところにバツ印がついていますが、PolarisはKubernetesのマニフェストのベストプラクティス違反を検出してくれるツールで、そこでエラーが出ればgitlab-commentで通知するようになっています。

長谷川:時間の関係で説明を省略しますが、gitlab-commentでの実際のレビューコメントはこちらのスライドをご覧ください。
長谷川:次は、CIパイプラインを各マイクロサービスに横断的に提供する方法です。この図は、一番上の共有リポジトリから、各リポジトリにCIファイルを配布していることを表しています。
このGitLab CIの設定ファイルですが、各Kubernetesのリポジトリは同じような実装になるので、やはり共有した方が管理が楽になります。GitLab CIにはincludeという機能があり、それを使うことで単一の共有リポジトリから、各マイクロサービスのリポジトリに配布することができます。GitLabに馴染みがない方もいらっしゃるかもしれませんが、GitHub Actionsにも類似するreusable workflowという機能がありますので、同じように実現できるかと思います。
また、各リポジトリで実施ステップやテストを任意で無効化できるオプションを用意して、切り替えられるようにしています。各マイクロサービスのリポジトリによって事情が異なると思いますので、あまり強制はしないようにしています。

長谷川:CIファイルがどのような実装になっているか紹介したいと思いますが、これも時間の関係で説明を省略するため、こちらのスライドを見ていただければと思います。2枚目のスライドは配布先リポジトリ、includeする側のCIファイルです。


長谷川:続いて、CDパイプラインを紹介します。CDパイプラインは、ArgoCDを現在およそ16個のプロダクトへ横断的に提供しています。図では、中央付近に横断的なArgoCD、上の方にArgoCDのデプロイ先のEKSがあり、下の方にはArgoCDをデプロイするSREや、マイクロサービスを実際にデプロイするマイクロサービスの開発者がいます。
ArgoCDには、どの範囲に影響を与えるかという認可を制御できるNamespacedスコープモードというものがあるので、それを使っています。各NamespaceのArgoCDは、対応するプロダクトのEKSにしかデプロイできない仕組みになっています。他にも、Keycloakを使ったシングルサインオンの導入、SOPSやAWSのKMSを使った機密データの暗号化、復号などもしっかり行っています。

長谷川:こちらの図が、とあるプロダクトを例に挙げて、ArgoCDの中身が具体的にどうなっているかを説明したものになります。これも時間の関係で、説明は省略させていただきます。

長谷川:CDパイプラインが止まってしまうと、マイクロサービスのデプロイできなくなり、生産性が下がってしまいます。なので、CDパイプラインを止めないために、いろいろなプラクティスを採用しているので、その取り組みを紹介したいと思います。
これはEKSの設計を表した図ですが、このEKSクラスターはプラットフォームチームで管理しています。EKSの中身を見ていただくと、ノードが2つあり、左側の管理ツールの方はManaged Node Groupで管理しています。右側のArgoCDのノードは、Karpenterがつくってくれたノードで管理しています。

長谷川:CDパイプラインを止めないために、いろいろな取り組みをしています。左側のツールで実現できるものとして、例えばDeschedulerでは不適切なノードからの退避ができますし、KarpenterではAWSの料金最適化ができたり、ノードのグレースフルシャットダウンができたりします。
先ほどお伝えした通り、現在プロダクトが16個もありますので、影響範囲が大きすぎる状態になっています。そのプロダクトの生産性を中長期的に支えられるように、こうしたさまざまなプラクティスを採用しているというわけですね。
また、ArgoCDにはapplication-controllerというコンポーネントがあり、レプリカ数をN+1にして可用性を高めています。こちらも時間の関係で説明を省略するため、スライドを見ていただければと思います。

長谷川:最後にまとめです。知見を標準化するために、より良いプラットフォームを設計導入するには、ステークホルダーとの横断的なコミュニケーションが必要でした。私はSREチームとプラットフォームチームを行き来し、コミュニケーションをとることで、より良いプラットフォームをつくることができました。
また、マルチプロダクトの組織では、コミュニケーションの溝によって、CI/CDの知見が分断されてしまう課題があります。それを我々プラットフォームチームが標準化し、各プロダクトに提供することで、マルチプロダクトの課題である車輪の再発明を防ぎ、生産性を支えることができました。
そして、プラットフォームエンジニアリングで各マイクロサービスの生産性を支えるため、各マイクロサービスに任意で無効化できるCIパイプラインを横断的に提供しました。これにより、ポリレポで課題になっているレビューの負荷を減らし、生産性を支えることができました。
以上で発表を終わります。ご清聴ありがとうございました。