 シェア
シェア はてブ
はてブ
24年6月28日、ファインディ株式会社が主催するイベント「開発生産性Conference 2024」が、開催されました。本記事では、GO株式会社の技術戦略部で部長を務める水戸 祐介さんによるセッション「タクシーアプリ『GO』におけるプラットフォームエンジニアリングの実践」の内容をお届けします。
『GO』の開発において、プラットフォームエンジニアリングを始めた背景や、5年以上の社内プラットフォーム導入を通して学んだ実践の鍵、そしてプラットフォームエンジニアリングの成果についてお話いただきました。
■プロフィール
水戸 祐介(みと ゆうすけ)
GO株式会社 技術戦略部 部長
2010年にクックパッド株式会社に入社、主にRailsエンジニアとしてサービス開発に従事。後半3年弱はスペインに出向して世界中に散らばったメンバーと共に海外向けサービスを開発。
2018年にJapanTaxiに入社し、GOの前身となるMobility Technologiesへの事業統合後も継続してSREとしてインフラ基盤開発や運用に携わる。主要サービスの共通基盤への移行などを通してタクシー配車サービスの安定運用に貢献してきている。
着実な成長を続けるタクシーアプリ『GO』の裏側
水戸:GO株式会社で技術戦略部の部長をしている、水戸と申します。約6年前に入社し、以来SREとしてインフラの基盤開発や運用に携わってきました。今日は、『GO』のSREが5年以上の社内プラットフォーム導入を通して学んだ、プラットフォームエンジニアリング実践の鍵についてお話したいと思います。
まず初めに、簡単にタクシーアプリ『GO』について紹介させてください。タクシーが呼べるアプリ『GO』は、アプリから今いる場所にタクシーを呼ぶという、シンプルな体験を提供しているサービスです。
『GO』自体のダウンロード数やタクシー実車数なども順調に成長しているのですが、それだけでなく、法人向けのサービスや脱炭素サービスなど、『GO』を中心としたさまざまな取り組みも続々と増えている状況です。こうした『GO』の裏側がどうなっているのかについて、ここから紹介していきたいと思います。
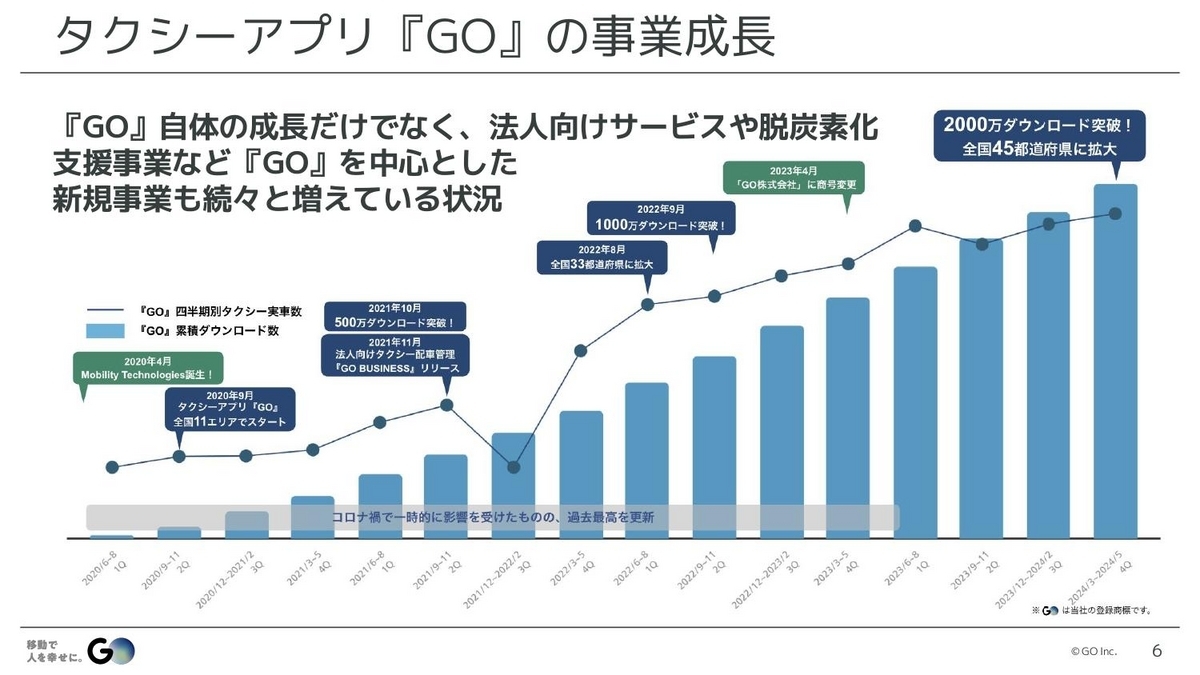
水戸:『GO』は、100以上のマイクロサービスで構成されていて、100人以上の開発者が10チーム以上に分かれて日々の開発を行っています。そして、この100以上のサービスの大半が、Kubernetesを中心としたKenosと呼ばれる社内プラットフォームの上で稼働しています。このプラットフォームは、マイクロサービスを素早く開発し、安定運用するためのさまざまな機能が提供されている基盤です。
ここからKenosの概要について、いくつかご紹介していきます。まず、このKenosクラスタ自体についてですが、大量のマイクロサービスを動かすための基盤となるクラスタになっています。『GO』では、このマイクロサービスというものを、いくつかのコンポーネントの組み合わせとして捉えています。
具体的には、多くのワークロードはAPIサーバー、非同期ジョブワーカー、定期実行バッチ、この3つのどれかになることが経験上わかっていて、1つのマイクロサービスは、このコンポーネントのいずれかを組み合わせたものだと定義しています。
例えばこの図のように、それぞれのコンポーネントが1つずつあるタイプや、APIサーバが2つあってジョブワーカーがあるタイプ、あるいはジョブワーカーがあってバッチが2つあるけれど、APIサーバがないものなど。こういった1つの塊をマイクロサービスとして定義し、これらを柔軟にデプロイできる仕組みをこのクラスタで提供しています。

水戸:次はCLIツールのknsというもので、Kubernetesにアクセスする場合、kubectlという標準のCLIがありますが、これをラップして簡単に使えるようにしたツールです。マイクロサービス環境での使用を前提にすることで、オプションなどが少なくアクセスできるシンプルな使用体験を提供しています。
例えば、開発環境のコンテナのログを表示したい場合、「kns dev logs」というコマンドをサービスのリポジトリで打つと、これだけでログが出てきます。kubectlでは、ポート名やラベルを指定するなど、いくつかオプションを把握しなければならないのですが、そういった必要がなく簡単にアクセスできるようになっています。
同じように、例えば本番環境のコンテナにログインしたい場合、「kns prod connect」とコマンドを打つと、これだけでログインできます。こういった便利なコマンドがいくつか用意されています。
また、kubectlを使ってより複雑な操作をしたい場合は、「kns dev cli」とコマンドを打ちます。すると、ローカルでkubectlなどが一通りセットアップされたコンテナが起動して、そこでコマンドが使えるので、開発環境の構築もあまり気にせずに実際のクラスタへのオペレーションができる形になっています。

水戸:次はマイクロサービスのテンプレートで、これはマイクロサービスをすぐに開発開始できるようになっているGitHubのリポジトリテンプレートです。開発からリリースまでに必要ないろいろな機能を、このテンプレートに含めることで、開発者がビジネスロジックだけに集中して開発できるようにしています。
例えばまず全体では、gRPCやRESTのサーバーが簡単につくれるフレームワークとして構成されています。ディレクトリ構成は、クリーンアーキテクチャベースになっていて、それぞれのサンプルコードもあるので、どこに何を置いたらいいかが簡単にわかるつくりになっています。
他にローカルで開発する場合だと、例えばMySQLやRedisなどのミドルウェアを立ち上げたいときがあると思いますが、そういったもののdocker-compose.ymlや、それを起動するmakeコマンド、あとは実際クラスタにデプロイするときに必要なDockerファイルやCI/CDの設定ファイルなど、そういったものが一式すべて初めから含まれています。
開発者はこれをもとにリポジトリをつくり、ブランチにプッシュするとクラスタにデプロイされるといった形で、他のことはあまり気にしなくても、ビジネスロジックだけに集中して開発できる仕組みになっています。

水戸:また、GOではGrafanaを使ったオブザーバビリティ基盤を提供しています。Kenosスラスタにデプロイしたマイクロサービスのメトリクスやログ、トレースは、すべてGrafanaで収集されていて、参照することができます。
ダッシュボードやアラートなどの一式が、あらかじめサービスごとに定義されているので、新しいサービスであってもリリース当初から、十分にオブザーバビリティが確保された状態で運用ができます。
また、ダッシュボードやアラートなどはすべて、サービスによらず全く同じ定義でつくられているので、初めて触るサービスであっても、以前触っていたものと同じような指標を見ることができます。なので、あまり内容のわからないサービスであっても、ひとまずここを見れば何となく何が起きているかわかるといった形で、学習コストが低く運用ができるようになっています。

水戸:最後はワークフロー基盤で、多段階の複雑なバッチを実行するための仕組みですね。これはApache AirflowとKubernetesを連携する形で使っていて、Kenosに乗っているサービスだと、簡単にジョブを定義して、それをAirflowのDAGと呼ばれるワークフロー定義から呼び出すことができるようになっています。なので、開発者はジョブ定義だけ行えば、複雑なバッチジョブが実行できる仕組みになっています。これは、例えば決済データの月次の締め処理などで利用されています。
こういった技術的な詳細は今回の発表の主眼ではないため、もし詳細についてご興味があれば、昨年発表した別の資料をご覧ください。
▶タクシーアプリ「GO」の少人数SREチームとマイクロサービス基盤
https://speakerdeck.com/mot_techtalk/sre-micro-service
※2023年3月時点の情報です。

GOがプラットフォームエンジニアリングを始めた背景
水戸:今プラットフォームをつくっているというお話をしましたが、そもそもプラットフォームエンジニアリングとは、プラットフォームをつくることなのでしょうか? これについては、もちろんそれはすごく重要なポイントではあるけれども、かといってプラットフォームをつくることが必須の要件でもないと僕らは思っています。
僕らにとってプラットフォームエンジニアリングとは、「サービスの非機能要件を標準化することで、開発生産性と品質を最大化する手法」だと捉えています。どういうことかというと、サービスをつくる中で、「これ誰か既にやったことありそうだな」と思うポイントっていろいろあると思うんですよね。
例えば、デプロイの仕組みやオートスケールの設定、監視ツールの設定など、そういった非機能要件では、同じようなことの繰り返しが多くなります。でも、それをバラバラにつくっていくと、毎回毎回それをやらなければいけない。それを標準化していくことが、プラットフォームエンジニアリングだと僕らは考えています。

水戸:では、ここからGOがプラットフォームエンジニアリングを始めた背景について、お話していきたいと思います。数年前のGOでは、AWSとGCPとAzure、3つのクラウドを使い、そのうえでEC2やApp Servicesなど、さまざまな仕組みを使ってサービスを動かしているという、非常に混沌とした状況がありました。
それぞれでデプロイやオートスケールなど、いろいろな仕組みを個別に実装して運用していて、それがしっかりできていればいいのですが、リソース不足で仕組みがつくり切れていないチームも多く、運用コストが高いまま運用が続けられている状況でした。
それによって、デプロイが属人化してしまったり、アラートが不足していて障害に気づけなかったり、ログが上手く検索できず問題調査に時間が掛かったりと、いろいろな運用の問題が起きていました。

水戸:また、SREとしても、サービスが乱立しているために、障害が起きてもなかなか状況を把握できずに手が出せなかったり、あるいは開発者が退職してしまって、メンテナがいないサービスが生まれてしまったりなど、いろいろな悩みがありました。
そこで、こうした状況を打開するために、SREとしては技術スタックの統一が必要だと判断し、SREチームを「標準化によって品質の改善と開発生産性の向上を実現するチーム」と定義しました。
標準化すれば、いろいろな作業を省力化できるので、それだけでもまず生産性の向上に繋がるだろうと。それだけでなく、標準化にあたっては、基本的に社内のベストプラクティスに近いやり方に統一することになるので、品質の安定化にも繋がると考えられます。
品質が上がれば、本番の障害が減ったり、開発中の手戻りが減ったりすることにも繋がるので、結果的に割り込みになるイレギュラーなタスクが減って、さらなる生産性向上に繋がります。こうした生産性向上と品質向上の両方が、標準化によって得られるだろうという考えを持っていました。

水戸:僕らSREのミッションは、「止まらないサービスを最速でつくる仕組みづくり」としています。これは品質向上と生産性向上、その両方を仕組みをつくることで解決するということです。そういったミッションで動き始めたのですが、最初はプラットフォームをつくるというより、まず身近な1つのサービスをKubernetesに乗せるところからスタートしました。
そこから徐々に、共通化できるものを見つけながら、いろいろなサービスをこのプラットフォーム上に乗せていき、その過程でプラットフォーム自体を改善しながら、移行や新しいサービスの導入を進めていきました。結果として、現在は大半のサービスがこのプラットフォーム上で動いている状態になっています。
SREチームがプラットフォームをつくっていることに、疑問を持たれる方もいるかもしれません。これはなぜかというと、僕らが始めたのが5年以上前で、そもそも当時プラットフォームエンジニアリングという言葉がなく、あまりそこに明確な区切りを考えていなかったためです。
ただ、現在でも業務特性の面から、プラットフォームとSREの業務はまだ分離しない方がいいと考えています。僕らが今実際にやっている業務を、プラットフォームとSREに分けたとすると、いわゆるDevOpsの文脈で、プラットフォームはDev寄りの業務、SREはOps寄りの業務になると感じています。これを単純に分離してしまうと、DevOps以前の時代のような、DevとOpsが対立する構造が生まれてしまうのではないかという危惧があります。
また、日々のオペレーションを繰り返すなかで、さまざまな課題が見つかって、それをもとにプラットフォームを改善していくというフィードバックも頻繁にあります。なので、ここを単純に切り分けてしまうと、そういったフィードバックが上手く働かなくなる懸念もあります。そのため、今後もずっとこうだと決まったものではないですが、しばらくはこの2つを分離せず、1つのチームでやっていこうと考えています。

5年以上にわたる実践のなかで、成否を分けた5つのポイント
水戸:こういった形でプラットフォームエンジニアリングを5年以上実践してきて、比較的上手くいっている現状に至るにあたって、いくつか成否を分ける重要なポイントがあったと感じています。ここからは、それについて順番にお話ししていきたいと思います。
まず1つ目は、責任境界を高いラインに設定することです。サービスの構造には、アプリケーションとインフラという領域があって、さらにアプリケーションの中には、機能要件と非機能要件があります。GOでは、開発者の責務は機能要件の部分で、SREの責務はインフラと非機能要件の部分と定義しています。
開発者はとにかくビジネスロジックの実装に集中し、SREはそれ以外の非機能要件全般の標準化やツールの開発、インフラの構築といったところに責任を持つということです。これによってインフラだけでなく、アプリケーションまで踏み込んでさまざまな標準化を行い、品質や生産性を担保しています。
例えば、先ほどお話ししたリポジトリテンプレートは、簡単に開発ができるという生産性向上の目的もありますが、一方でサーバーを安全にグレースフルシャットダウンできるなど、サービスとして正しく動いてほしい部分を担保する役割もあり、運用の品質を上げる効果があります。
そういったところを開発者にすべて任せてしまうとバラつきが生まれて、運用上困るケースが出てくるリスクがあります。なので、そこまで踏み込むことで、全体の品質と生産性の両立をしているというのが、この責任境界です。
非機能要件までを責任範囲とした理由ですが、これは標準化できるところを標準化し続けてきた結果、この境界になりました。機能要件というのは、その名の通りサービス固有のロジックなので、本質的に標準化できるものではないんですね。それがサービスの価値そのもので、他にあるならつくる必要はないですから、標準化できない領域です。
一方で、非機能要件はサービスに依存しないロジックで、いろいろなサービスを横断して同じようなことをやっている領域なので、標準化しやすい。インフラも同じように、どんなアプリケーションが動いているかはあまり関係ないことが多いので、ここも標準化しやすい。この標準化しやすい2つの領域を標準化してきた結果、今この境界が僕らの責任範囲になっています。

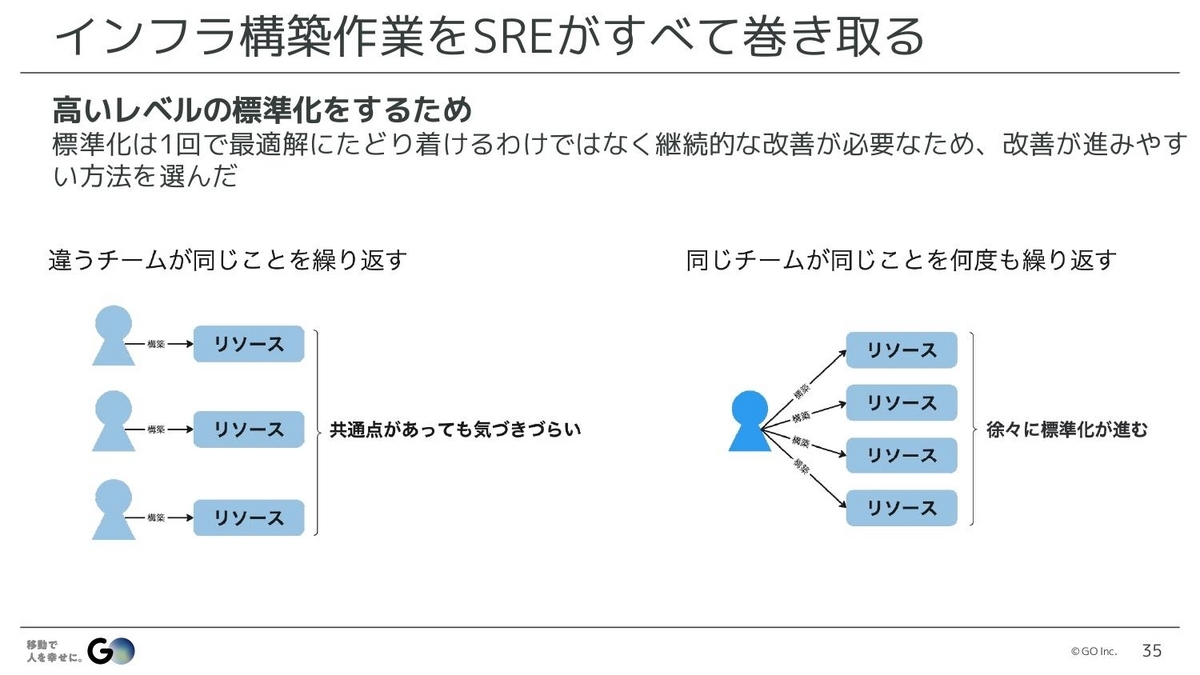
水戸:2つ目は、インフラ構築作業をSREがすべて巻き取ることです。GOでは、AWSとGCP上のインフラ構築は、すべてSREが実施しています。インフラ構築の責務のパターンとしては、開発チームがあらかじめ用意された共通モジュールなどを使い、自分たちで構築するパターンと、SREチームがすべて構築するパターンの2つがあると思います。
一般的にプラットフォームエンジニアリングの文脈では、1つ目のパターンが推奨されていると思いますが、僕らはあえて2つ目のパターンを採用しています。なぜかというと、高いレベルの標準化をするためです。標準化というのは、なかなか1回で最適解にたどり着けるわけではなく、多くの場合、一度決めたものを少しずつ改善しながら、より良い形の標準を見つけていく必要があります。
これを最初から開発チームにデリゲートしてしまうと、1つの開発チームが同じようなリソースを何度もつくる経験はなかなかしないので、他のチームと自分のチームがやっていることに共通点があったとしても、気づきにくいと思うんですね。
逆に、1つのチームがいろいろなチームのリソースを何度もつくっていると、その中で共通点が見えてきて、標準化すべきポイントもわかりやすくなっていく。そういった気づきを得やすくするために、SREチームがすべて構築する形をとっています。
ただ、それをやるとSREが大変すぎると思われるかもしれません。実際にその通りで、特に最初の2~3年は標準化されていないものばかりで、負担は大きかったです。ですが、そこで諦めず地道にさまざまな部分の標準化を続けていくことで、だんだん依頼が既存のパターンにはまることが多くなり、徐々に楽になっていきました。結果として、今はこういったやり方でも耐えられるレベルの負荷になっています。
水戸:3つ目は、サービスのアーキテクチャレビューを行うことです。GOでは、開発チームがいろいろなマイクロサービスのアーキテクチャ設計をしますが、その後に必ずSREがレビューするようにしています。これは、標準の維持が一番の目的です。
標準化を進めるなかで、例えばライブラリになっていたり、何らかの仕組みになっていたりすることもたくさんありますが、一方でなかなか明確に言語化したり、仕組みにしたりするのが難しいレベルの標準もあります。すべてが完璧に仕組み化できているわけではないので、そういったものをレビューを通して直しています。
特に重視しているのが、同じ課題は同じ方法で解決するということ。例えば、キャッシュサーバーを用意したいときに、Redisを使うかMemcachedを使うかという選択肢があったとして、僕らは基本的にRedisを使うことにしています。もう1つの例として、非同期処理に何らかのキューが欲しいとき、SQSを使うかRDBを使うかといった選択肢がありますが、僕らはSQSを使うことにしています。
これは決してMemcachedやRDBが悪いわけではなく、同じ課題には必ず同じ方法を使うことを重視しているために、こういった選択をしています。ただし、標準の選択肢で解決できない課題が出てきたときには、別の技術を使うことは厭いません。
標準を揃えることにこだわる理由ですが、どんなものでもつくった後に少しずついろいろな問題が起きて、それを解決していかなければなりません。それを持続的に行っていくためには、発生する問題のパターンをできるだけ収束させて、問題解決のコストを最小化させる必要があります。
例えば、同じ課題なのに違う方法で実装してパターンがどんどん増えていくと、問題が起きたときに、そのパターンでしか起きない問題が発生していくと思うんですね。そうすると、いろいろなところで個別解決が必要になり、解決が全然スケールしていきません。
逆に、同じ課題を同じやり方で解決していれば、1ヶ所で問題が起きたら、それは他の場所でも起きるということなので、同じ解決方法でさまざまな場所に水平展開できます。そうすると、まだ問題が起きていないうちに未然に解決できる場合もあり、解決にかかるリソースがすごくスケーラブルになります。そういった理由から、標準に揃えることにこだわっています。

水戸:4つ目は、完璧なプラットフォームを目指さないことです。GOでは、プラットフォームの長期ロードマップを持たず、常に次の半年につくるものだけを決めて、プラットフォームを改善してきています。なぜかというと、僕らがつくっているのは世の中にリリースするためのプラットフォームではなく、あくまで社内のプラットフォームだからです。
プラットフォームとして、「きっとこんな機能があったほうがいいだろう」と思うものはさまざまありますが、世の中では一般的にニーズがあるものでも、社内でニーズがないなら、つくっても意味がないんですね。そして、社内の状況は常に移り変わっていくので、今この瞬間どのような課題があるかを考え、それにマッチする解決策を実装していく。そういったやり方をとっています。
ただ、長期プランがないからといって、場当たり的な改善をしているわけではなく、しっかりと設計し、疎結合なコンポーネントをつくっています。そういった要素を積み上げていくことで、全体的な長期プランがなくても拡張性を維持しながら、さまざまなコンポーネントが上手く繋がり合っていくようにプラットフォームを形成していっています。

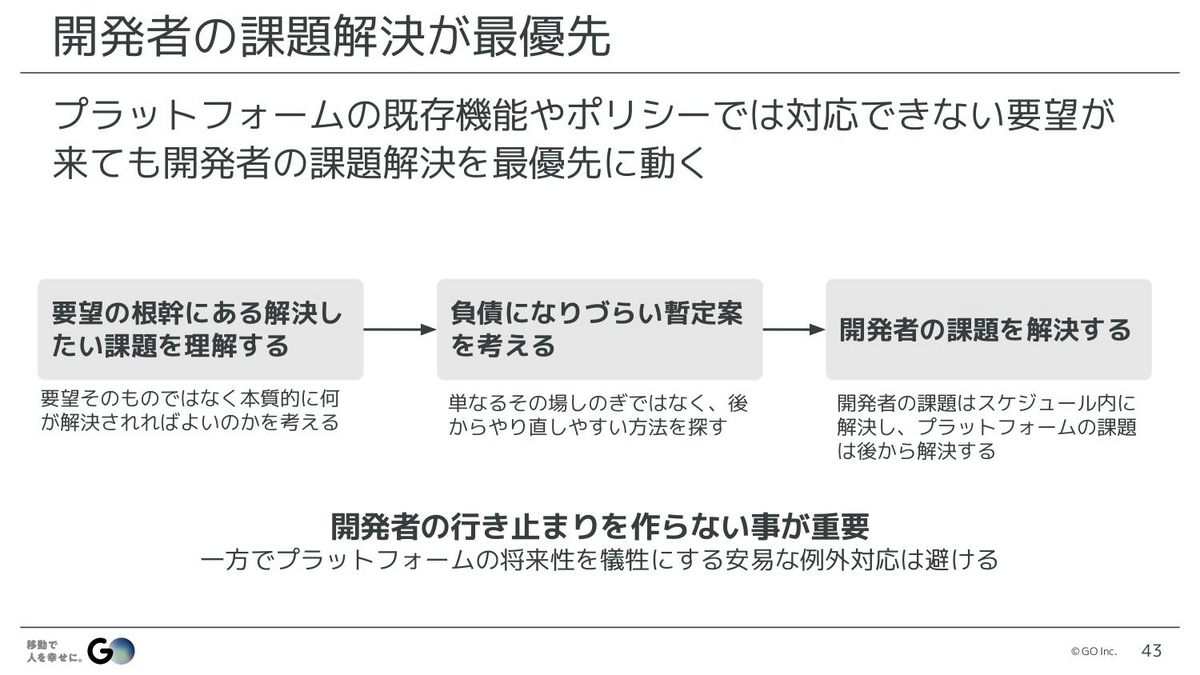
水戸:最後の5つ目は、開発者の課題解決を最優先にすることです。プラットフォームをやっていると、既存の機能やポリシーでは対応できない要望が来ることが多々あります。そういったときに、例えば「対応していないのでできません」と、そこで終わってしまったり、あるいは逆に無理やり対応しようとして、標準から大きく外れた例外対応を積み重ねてしまったり。そういったやり方を、僕らはできるだけしないようにしています。
そういう要望が来たときには、まず要望された機能そのものではなく、なぜそれを欲しいと思ったのかという課題を理解することからスタートします。そして、お互いに何を解決したいのかがわかったところで、それでもやはり今の機能では解決できないといった場合、開発者にはスケジュールがあるはずですから、そのスケジュール内でプラットフォームを改善して対応できるなら、基本的にその手段を取ります。
ただ、大きな改修をしないと対応できないこともあるので、そういった場合には、何らかの暫定策を取る必要があります。その場合も、開発者のスケジュールを守ることを最優先としつつ、プラットフォームにとっても負債にならない、場当たり的な対応にならないやり方を考えて暫定案を提案し、開発者の課題は必ずスケジュール内に解決するようにしています。
プラットフォームの課題は、スケジュールの縛りがなくなった後に、より正しいと思えるやり方でやり直します。あくまで、僕らの仕事はプラットフォームをつくることではなく、生産性と品質を上げることなので、開発者が行き止まりの状況にならないように助けることが大前提です。とはいえ、長期的に正しいやり方をしないと、結局いつかはみんなが苦しむことになるので、その両方のバランスを取りながら課題解決をしています。
プラットフォームエンジニアリング実践による成果
水戸:このように、いろいろなポイントを意識しながらプラットフォームをつくってきた結果として、今どういった成果になっているかを最後にお話ししたいと思います。まず、このプラットフォーム上では今、平均して毎週20サービスが45回以上、本番環境にデプロイしています。さまざまなサービスが同時に、アクティブに開発されていることがわかるかと思います。
また、いろいろな自動化やオブザーバビリティの充実によって、開発者自身でのサービス運用が実現できています。例えば、デプロイやロールバックはSREの承認など一切なく開発チームが行えますし、アラートが起きたときの一時対応も、基本的には開発チームが行います。アプリケーションのバグなどの対応も開発者がしています。
大きな障害が発生したときには、SREチームも一緒にサポートして障害解決にあたりますし、インフラ起因の問題であれば、当然僕らが解決に向けて動きます。障害でなくとも、難易度の高い性能の問題などが起きたときには、僕らが実際にコードを修正するレベルまで深く入って、一緒に問題を解決します。
ただ、SREチームは各サービスのオンコールには入っておらず、電話が鳴るのはまず開発チームです。サービスに深刻な影響を与えるような大規模なエラーの場合には、SREの電話も鳴りますが、細かいところで毎回SREが呼ばれることはない運用体制になっています。

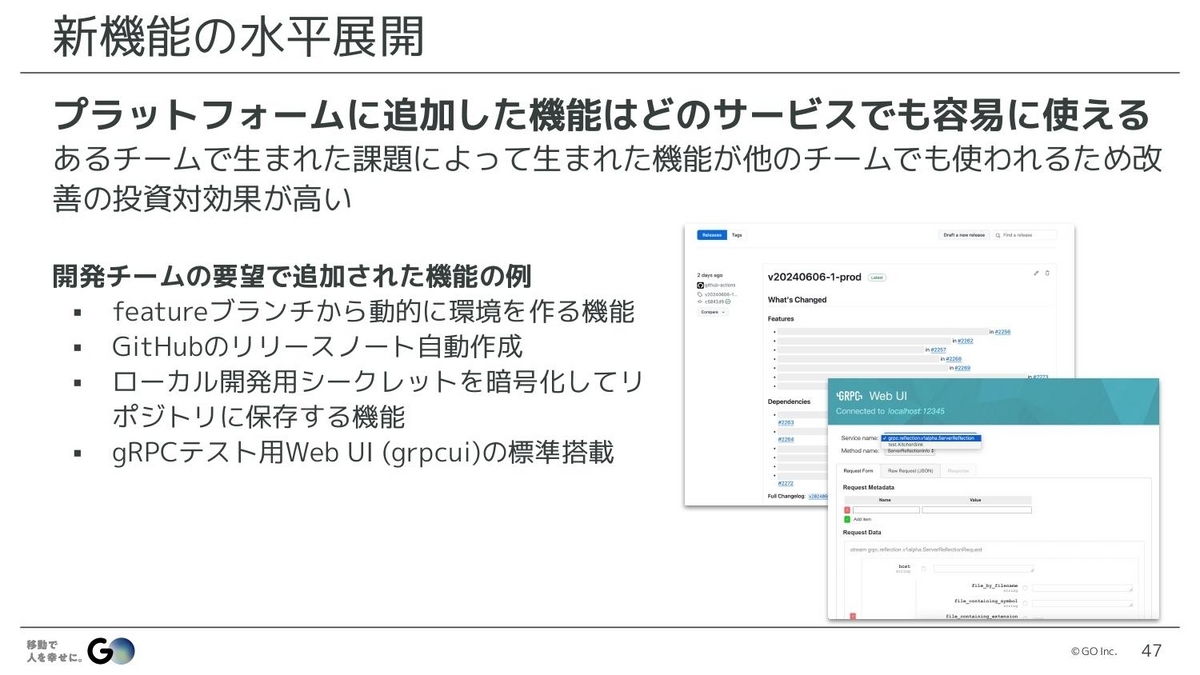
水戸:次は、新機能の水平展開です。プラットフォーム上で動いているサービスの構成はとても一貫性のある状態になっているため、どこかのチームで生まれた課題によって実装された機能は、他のチームでも簡単に使えるようになっています。なので、1つの改善が全体に波及する、投資対効果が非常に高いアクションができる状態になっています。
実際に追加された機能の例としては、フィーチャーブランチにプッシュすると動的に環境が増える機能や、本番リリースをするとGitHubのリリースノートが自動的に作成される機能、開発環境において開発者間で共有したいシークレットを安全に暗号化してリポジトリに保存できる機能などがあります。
場合によっては、開発チームがつくっていたもので良い機能があれば、僕らがそれを全体で使えるように、例えばテンプレートに入れるなどの動きもしています。
水戸:次は、インフラ構築の効率化です。先ほどSREチームがすべての構築をしているとお話しましたが、実際の依頼数として、毎月平均1~2つのマイクロサービスを新規構築している状況です。さらに毎週数回、既存サービスの構成変更の依頼が来たりもします。
もちろん負担はありますが、新しいサービスであれば最短リードタイム1日程度で構築できますし、既存サービスの構成変更であれば、数十分程度で終わるものが大半です。なので、開発スケジュールにおいて、インフラ構築の工数は厳密に計画していません。
開発者のリソースはしっかり工数管理していますが、SREに関しては、そういった管理を一切しておらず、オンデマンドなやり方で対応できるレベルに収まっています。これはやはりインフラ構成や構築手順など、いろいろなものを標準化したことで、かなり高い効率で構築作業が行えているからだと思います。
水戸:また、サービス構成が一貫していることで、SREチームがとてもレバレッジ効果の高い仕事をすることができています。例えば、すべてのマイクロサービスに変更が必要な、大規模なツールの導入をする場合、開発者に依頼することなくSREだけで対応できています。
具体例を挙げると、すべてのマイクロサービスのCI/CDの設定を、Travis CIからGitHub Actionsに変更したことがありました。これはすべてのリポジトリのymlファイルを書き換える必要がありますが、どのリポジトリもある程度同じような定義になっているので、比較的単純作業で置き換えられます。
量は多いですが、やることは単純なので手分けしてやり切り、開発者は何もタッチしないうちに、いつの間にかGitHub Actionsに変わっているといった形で対応しました。
同じようにオブザーバビリティの基盤も、以前はNew Relicを使っていたのですが、いろいろあってGrafanaに置き換えるという意思決定をしました。その際、Grafana自体の構築以外に、既存のダッシュボードやアラートなどもすべて移行する必要があります。
何十個もあるマイクロサービスに用意されていたダッシュボードやアラートは、数百個か数千個くらいの定義がありましたが、これも元の定義がTerraformですべて共通化されていたので、その共通の仕組みをGrafanaベースのものに書き換え、それぞれに適用していけば、すべてGrafana版のものが出来上がります。
これも面倒な作業がたくさんありますが、基本的には単純作業で、大量の単純作業であればスクリプト化できるところもあります。なので、これも1人のSREが全サービスのものを書き換えるといった形で対応しました。
開発チームは、機能の開発でリソースがいっぱいになっていることが多いので、それ以外のことになかなか手が回らないと思うんですね。なので、こういった大規模な変更を開発者に依頼してやってもらおうとすると、すごく時間がかかるうえに、なかなかすべて置き換えるのは難しいということになりがちです。
僕らは構成が一貫していることで、開発者に依頼せず、比較的短時間で徹底的に全部を置き換えることができるので、一切古いやり方が残っていない状態にできることが強みになっています。

水戸:さらに、マイクロサービスはどれも構成がほぼ同じになっているので、オペレーションや構築作業も同じ手順で行えます。なので、SREのメンバーは緩やかに担当するサービスが決まってはいるものの、自分の担当ではないサービスでも基本的なオペレーションができ、属人性がほとんどない形で対応できています。
ここまでお話ししてきたプラットフォームの開発や運用、インフラ構築や開発者のサポートなどは、今すべて5名のSREチームで行っています。開発者は100人くらいなので、100対5ですが、こういった運用ができているのは、いろいろなものが標準化されていることの結果だと思っています。
それでは、まとめです。プラットフォームエンジニアリングを実践してきて学んだことは、プラットフォームエンジニアリングというのは、持続的な標準化の営みだということ。僕らは確かにプラットフォームをつくっていますが、それが目的なのではなくて、いろいろな状況に対応しながら標準化という手法を使い、継続的に品質や生産性を向上していく、その活動自体がプラットフォームエンジニアリングではないかと考えています。

最後に、簡単なお知らせです。こういった開発環境で実際にサービス開発をしてみたいと思われた方は、ぜひ弊社の採用サイトを見ていただければと思います。また、いろいろな技術情報をXのアカウント(@goinc_techtalk)にて公開しています。弊社では、AIまわりなどにも力を入れて開発していますので、ぜひご興味があれば見てみてください。では、以上で発表を終わりたいと思います。ありがとうございました。
▶GO株式会社 採用サイト
https://goinc.jp/career/