 シェア
シェア はてブ
はてブ Rubyをはじめとする「動的型付け」のプログラミング言語は、ソースコード中に型に関する記述が陽に出てこないことが特徴で、プログラムの実行前に(静的に)型検査をすることはありません。しかし、このようなプログラミング言語においても、大規模な開発における品質の向上や開発体験の改善、実行の高速化のために、静的な解析を活用しようという試みは多くなされてきました。この記事では、動的型付けの言語のための型検査の歴史を簡単に振り返って、現在私が開発しているRuby向けの型検査器Steepとその基盤となっている型記述言語RBSについて説明し、今後の展望を議論します。
Rubyをはじめとする「動的型付け」のプログラミング言語は、ソースコード中に型に関する記述が陽に出てこないことが特徴で、プログラムの実行前に(静的に)型検査をすることはありません。しかし、このようなプログラミング言語においても、大規模な開発における品質の向上や開発体験の改善、実行の高速化のために、静的な解析を活用しようという試みは多くなされてきました。この記事では、動的型付けの言語のための型検査の歴史を簡単に振り返って、現在私が開発しているRuby向けの型検査器Steepとその基盤となっている型記述言語RBSについて説明し、今後の展望を議論します。
著者:松本宗太郎さん(@soutaro)
Rubyコミッター。大学院でRubyプログラムの型検査の研究に取り組み、修了後はスタートアップでWebアプリケーションの開発に従事。2017年から型検査ツールSteepの開発を始め、2019年からはRubyコミッターとしてRuby標準の型定義言語RBSの開発を主導する。2024年4月、タイミーにフルタイムRubyコミッターとして入社。博士(工学)。
型付けに関する戦略
プログラミング言語の分類にはさまざまな基準がありますが、ここでは型付けについて分類してみましょう。型付けに関する戦略を大きく分けると、プログラムの実行前に型検査を行う「静的型付け」と、プログラムの実行中に型検査を行う「動的型付け」があります。実際には静的型付けの戦略に基づいて実装されているプログラミング言語でも、実行時にある種の型検査を行うことはよくありますので、もう動的型検査は行うことを前提にしてしまって「静的な型検査を提供する/しない」という分類で考えたほうが良いかもしれません。
静的な型検査が提供され、なおかつ動的な型検査が言語機能として標準的に利用されていないものには、CやOCaml、Rustなどがあります。逆に、動的な型検査は提供されているが、静的な型検査が提供されていないプログラミング言語には、RubyやJavaScriptなどが含まれます。
char *str = "C"; int i = (int)str; // Cのキャストは実行時の検査を行わないのでプログラムの実行が続く
両方が提供されているもの、つまり静的な型検査が提供され、さらに動的な型検査が標準的に利用されているものには、JavaやSwiftなどの多くのプログラミング言語が含まれます。Javaではダウンキャストの失敗は java.lang.ClassCastException によって、例外として通知されます。Swiftでは as? 演算子・ as! 演算子によってダウンキャストを行いますが、こちらも型検査の結果に応じて失敗することがあります。
String str = "Java"; Integer i = (Integer)str; // Javaのキャストは失敗して例外が発生する
現代のプログラミング言語では、実行時の型検査は標準的に提供される機能であり、プログラミング言語や外部ツールによっては「静的に型検査を行うレイヤーが追加されることがある」といった感じで認識するのが良いかもしれません。(もちろん、Rustを考えればわかるように、実行時の型検査を提供しない戦略を採用する言語も残っています。)
静的型付けは難しい
静的な型検査と動的な型検査のそれぞれの得失については、次のように考えることができます。
静的な型検査は、ソースコードを網羅的に検査して問題が発生する可能性がある部分を検出することができます。一方で、実行される可能性のある全ての場合について検査をするので、「実行時には発生し得ない」条件分岐についても、型の整合性が成立している状態にしなくてはいけません。
if Math::PI == 3.0 "Hello" + 123 # このブランチは実行されないが静的型検査がエラーを報告してしまう end
上のRubyプログラムを実行しても型エラーは発生しませんが、これを正しく型検査できるツールは(ほとんど)ありません。Math::PI が円周率を保持していること、円周率は3.0ではないことなどの知識を型検査ツールが備えていない限り、 if 式の条件が成立しないことを判断できないので、if の中で型エラーが報告されてしまいます。これはほとんど自明な例ですが、「配列の要素が空でないので、必ず要素を取り出すことができる」のような少し複雑な条件を考えるだけで、正確な解析は現実的でなくなります。言い換えると、静的型検査は問題を誤検出することは許容しても、問題を見逃すことは極力避けるように設計されています。
動的な型検査は、実行中に実際に問題が発生したときだけ考えれば良いので、プログラミングしている最中に型検査器によって理不尽に文句をつけられることはありません。ただし、プログラムの規模が大きくなると、人間が想定していない条件分岐の組み合わせが発生することもあるので、テストで検出できないとプロダクション環境にデプロイしてからエラーが起きることになります。
これらは利用者からの視点ですが、実装する側の視点ではどうでしょうか?実装者の観点でも、静的型検査は考えることが増えます。単純な型システムは簡単に実装できますが、利用者により自由にプログラミングしてもらうためには型システムと型検査アルゴリズムは複雑になっていきます。動的型検査であれば、実行中に問題が発生した瞬間だけ考えれば良いので、実装として圧倒的に簡単になります。(しかも、先に述べたように、結局動的型検査も必要になります。)
教科書的には動的型付けのプログラミングで大規模なソフトウェアを開発するというのは賢い選択ではありませんが、現実には数多くのWebアプリケーションがRubyやJavaScript、PHPなどの動的型付けのプログラミング言語を利用して開発されています。動的型付けによって得られる柔軟性から高い生産性を確保し、テストを充実させることによって型検査がないことによる問題を克服する、というのがプログラム開発の一つの成功パターンであるというのは、現時点で我々が共有できる結論の一つであると思います。
一方で、静的な型検査に利点があることも確かなことであり、動的型付けの言語に静的な型検査を導入するための試みもなされてきました。
静的な型検査を後付けするために必要なものとは
1982年に関数型プログラミング言語であるMLで型推論アルゴリズムが発明され、「型宣言をいちいち書かなくても静的な型をプログラム自体から抽出できる」ことがわかりました*1。この研究を発展させて、同様に型宣言がプログラムのソースコードに埋め込まれていない動的型付け言語に対して型検査を追加できないかについて、盛んに研究されたことがありました。
Soft typingと呼ばれるプロジェクトは、Schemeという動的型付けのプログラミング言語を対象に静的型検査を追加するもので、この分野の研究では一番古いものの一つです*2。このプロジェクトが実際の動的型付けのプログラミング体験に大きなインパクトを与えることはありませんでしたが、いくつかの重要な知見が得られました。その中でもここではUnion型に注目します。
動的型付けのプログラミング言語では、次のような複数の種類のオブジェクトを返すメソッドを書くことができます。
def f(x) = x ? 1 : "A" # 1か"A"が返り値となる
実際にこのメソッドを呼び出した結果得られた値を使うときには、動的な型検査によって返り値が Integer か String のどちらかを確認してから使うことになります。(Integer か String というとあまりなさそうな気がしますが、「成功したときに何かの値を返し、失敗しときには nil を返す」だと、そこそこ頻繁に目にすると思います。)
このようなプログラムを型検査することを考えると、Union型とFlow-sensitive typingが必要になります。つまり、メソッドの返り値の型として「Integer か String のどちらか」を意味するUnion型を与え、さらにFlow-sensitive typingによって動的な型検査の結果に応じて Integer か String のどちらかに限定した型を復活します。
a = f(rand(2).even?) # aの型はStringかIntegerのどちらか(Union型)になる if a.is_a?(String) # aの値がStringであることを確認し、then節とelse節の型検査ではその情報を利用する # ここではaの型はStringとする else # ここではaの型はIntegerとする end
if で is_a? メソッドを使って、 a の値が String であることを確認した後は、その then 節では a の型を String として使うことができます。また、 else 節では Integer となります。このように、動的な型検査の結果を利用して、プログラムの実行状況に応じた型付けを行うFlow-sensitive typingにより、より正確な型検査が可能になります。
ここまでで、Union型などの機能があれば既存の動的型付け言語のプログラムもそれなりに型検査ができそうだとわかりました。一方で、これらの機能があると途端に型推論は難しくなり、MLで成功して既に確立されているアルゴリズムは流用できません。つまり、型推論によって動的型付けの言語で書かれたプログラムを解析するのは、簡単ではなさそうです。
ちなみに、私が学生時代にやった、MLとよく似たプログラミング言語であるOCamlの、オブジェクトに関する型推論アルゴリズムをRubyに適用する研究でも、このUnion型は問題になりました*3。さらに、OCamlが前提とする型システムを利用した場合には、そもそも標準ライブラリに含まれるクラスの型を表現することが困難であるという結論が得られました。
もう一つの潮流はGradual typing(漸進的型付け)によってもたらされました*4。Gradual typingは、静的に型付けされた部分と動的に型付けされる部分を、一つのプログラムに混在させることを目的とするもので、動的に型付けされる部分を徐々に(漸進的に)減らしていくことを目指します。具体的には、静的に型付けできない部分を特別な ? 型として表現することによって、型付けされないものを含むプログラムを静的に型付けすることを可能にします。このテクニック自体はことさらに新しいものではありませんでしたが、動的型付けのプログラミング言語を取り扱う上では都合が良く、これらのプログラミング言語に対する静的な型検査を提供するツール群は同様のアイデアに基づいた型を導入していきました。
TypeScriptの成功
これらの知見を踏まえて開発されたTypeScriptは「型の宣言を埋め込むことができる、JavaScriptに変換される新しい言語」という野心的なものでした*5。TypeScriptには any 型が提供されており、Gradual typingの ? 型と対応しています。型がわからないものは any 型として扱い、さらにGenericsやUnion型などの機能を活用することで、さまざまなプログラムを解析することができるようになりました。ユーザーはTypeScriptのプログラム内に型を書くことによって静的型付けの利点を活用しながら、既存のJavaScriptライブラリや処理系をそのまま使い続けることができます。
document.addEventListener("DOMContentLoaded", (event: Event): void => { const title: HTMLHeadingElement = document.createElement("h1"); title.textContent = "Hello TypeScript!"; document.body.appendChild(title); });
このTypeScriptプログラムは、 addEventListener に与えられたコールバック関数の型や title 変数の型が注釈として追加されていますが、JavaScriptと同様にDOMを使ったプログラミングが可能なことが示されています。(実際にはこれらの型注釈は省略できますが、省略するとただのJavaScriptプログラムになってしまうので、説明のために追加しました。)
TypeScriptが登場したとき、私にはあまり魅力的なものに見えませんでした。JavaScriptの動的な性質を捨てて、TypeScriptに乗り換えるというのはあまり現実的には思えなかったのです。TypeScriptへの移行にはソースコードの書き換えも必要になりますが、既存のJavaScriptのプログラムをTypeScriptに書き換えていくというのはなかなか厳しい要求です。動的型付けのプログラミング言語に似せた静的型付けのバージョンを開発する、というプロジェクトは既にいくつか存在しており、それらと同様に大きな成功は見込めないものに感じられました。
しかし、TypeScriptは大成功を収めています。Soft typing以来、我々の頭の中にあった「既存のプログラムをそのまま書き換えずに型検査しなくてはならない」という前提は、もう少し緩めてもよかったようです。ライブラリや実行環境などの魅力的な資産が既に十分にあり、高機能な開発環境が提供される場合には、ソースコードの書き換えというのは乗り越えられる問題のようです。
Rubyに静的な型検査を追加するために
私はRubyに型検査を追加するためにSteepというツールを開発しています。Steepでは、既存のRubyプログラムをそのまま解析すること、つまり型推論によってユーザーに型を書かせないことはあまり重視しておらず、「普通の静的型付けの言語と同様な体験」を提供することを重視しています。クラスやメソッドの型は人間が宣言し、Steepは実装と型宣言の間に矛盾がないかを検査します。
Rubyの静的型付けとして特徴的な点は、Rubyの構文を拡張していないところで、RBSという別の言語で記述された型定義ファイルによって型を宣言することです。また、Steepで型検査をする際に、どうしても必要になるプログラム中の型注釈はコメントとして記述します。
class Article attr_reader title: String attr_reader content: String def initialize: (String title, String content) -> void def slug: () -> String end
これはRBSによるクラス宣言の例で、Article というクラスに title と content というアトリビュートがあり、それらの型が String であることが示されています。また、 initialize と slug というメソッドが定義されていることが示され、それぞれの型が与えられています。この Article クラスの実装の例は次のようになります。
class Article attr_reader :title, :content def initialize(title, content) @title = title @author = author @content = content end def slug = title.gsub(/\s/, "-").downcase end
別のファイルに型を宣言するというのは、CやC++のヘッダファイルと似た発想で、OCamlの .mli とも似ています。また、RBSファイルはRubyの構文に似せてはいますが、Rubyとは別の言語で、メタプログラミングの要素を取り除いていることも特徴です。つまり、RBSファイルを読むだけで、どういうクラスやメソッドが定義されているのか、ほぼ自明に読み解くことができます。そして、この型定義と実装の間の矛盾を検出するのが、Steepの主な機能ということになります。
この設計にはRubyの設計者であるまつもとゆきひろ(Matz)の考えが強く反映されています。Matzの主張を一言でまとめるなら、「今後の静的解析器の発展によって、型を書かない時代がいずれまた到来するから、Rubyプログラムに型を書けるようにはしない」というものです。この方針は「別のファイルに型定義を追い出す」というRBSの設計における根拠の一つです。
RBSによって記述された型情報は、Steep以外からも利用することができます。TypeProfという静的な型検査ツールや、irbの補完に活用するrepl_type_completor、RDocのドキュメントと合わせて表示するrubyapi.orgなど、さまざまな用途に活用されています*6*7*8。
RBSとSteepの機能
RBSではいろいろな型が提供されており、Steepにも現実のRubyプログラムを解析するときに必要になるさまざまな機能が実装されています。
メソッドのオーバーロードは主に標準ライブラリの型を提供するときに必要になるものですが、ユーザー定義のメソッドでも利用することができます。
class Integer def +: (Integer) -> Integer | (Numeric) -> Numeric end
Genericなクラスが定義できるので、さまざまなコレクションを自然に定義できます。また、Genericなメソッドも定義できるようになっています。
class Array[Element] def map: [T] () { (Element) -> T } -> Array[T] end
RBSではUnion型が提供されており、SteepではFlow-sensitive typingも実装しています。nil とのUnion型を表現するOptional型と組み合わせて、 nil に対して安全なプログラミングを実現できます。
x = [1, 2, 3].pop # xの型は Integer | nil (Integerかnilのどちらか。Optional型を使って表記すると Integer?) if x # xの型は Integer (ifで確認しているので、nilにはならない) x + 1 end
x の型は Integer | nil なので、そのまま + メソッドを使って Integer の足し算を計算することはできません。しかし、Flow-sensitive typingによって、 if の中では x が nil ではないことがわかるので、足し算が計算できます。このように、Optional型を使うと、nil でないことを確認しない限りメソッドを呼び出すことはできないので、うっかり nil のメソッドを呼んでしまって NoMethodError が発生することがなくなります。
これらの機能によって、既存のRubyコードをそれなりに精度良く解析することができるようになっています。メソッドの型を書くことは必要ですが、メソッドの実装は大幅に書き換えなくても型検査ができるようになっています。
言語サーバによるIDEとの連携
Steepではそれなりに早い段階からLanguage server protocolに基づく言語サーバ(Language server)の機能を提供しており、VSCodeをはじめとする各種IDEやエディタとの連携が実装されています。
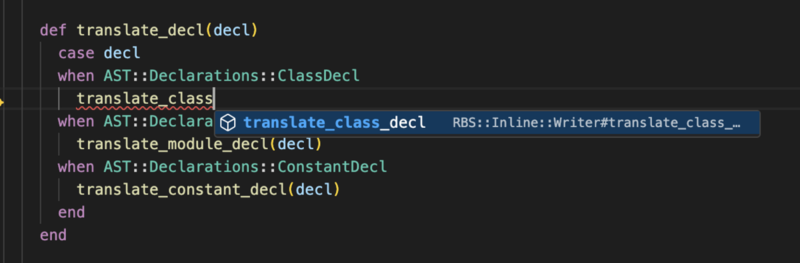
translate_class_decl メソッドの名前が補完候補に表示されています。また、入力中の translate_class にはメソッド名が存在しないとエラーが報告されています。
言語サーバによってIDEからSteepの解析結果にアクセスできるようになっており、メソッドやクラスの定義へのジャンプ、エディタ内でのエラーの報告などの機能が提供されています。むしろ、Steepにおいて型検査そのものは重要な機能ではなく、それよりもIDEでのソースコードの記述・読解の支援こそが主要な機能であると位置づけています。
メタプログラミングの取り扱い
メタプログラミングはクラス定義やメソッド定義のための構文を利用せずに、メソッド呼び出しによってそれらを定義するもので、Rubyの柔軟性を支える大きな柱の一つです。
Author = Class.new(ApplicationRecord) do has_many :articles end
この3行のプログラムにはクラス定義の構文もメソッド定義の構文も含まれていませんが、 ApplicationRecord クラスを継承した Author クラスを定義し、 articles というメソッドと、さらに多くの関連するメソッドを定義しています。さらに has_many というメソッドは ActiveRecord というライブラリで定義されるものであり、Rubyの標準のものでもありません。Rubyでは、メタプログラミングによってメソッドを定義するメソッドを簡単に定義することができ、さまざまなライブラリで活用されています。このようなRubyの性質を幅広くカバーするような型システムを定義することは困難で、現実的ではありません。
しかし、よく考えてみると、メタプログラミングにおいても実行するまでどういうメソッドが定義されるかわからないことはまれであり、実際には特定の挙動をする特定の名前のメソッドを簡易に定義するために利用されることがほとんどです。つまり、どういうメソッドが定義されるのかは、メタプログラミングを利用するRubyプログラムにおいても事前にわかっていると言えます。
この考察に基づき、RBSではメタプログラミングは単に無視することにしました。メタプログラミングを活用したプログラムにおいても、どういうメソッドが定義されるのかはあらかじめ決まっていることが多いため、そのメソッド群をRBSに書き下してもらうことはできるはずです。そして、全部書いてもらったRBSを元に型検査をすれば、Rubyプログラムの型検査ができます。
実際には全てのメソッドを書き下すというのは簡単ではありませんが、ライブラリやフレームワークの知識を活用したジェネレータが活用されています*9*10。
今後の展望
RBSとSteepによるRubyプログラムの静的な型検査は、それなりの成功を収めつつあると認識しています。RBSとSteepの実装はそれぞれSteepを使って型検査をしながら開発していますし、そもそもTypeScriptを考えればこの方針がある程度の成功を収めることは自明と言えます。一方で、現実にもっと広く利用されるためには難しい点があることもわかっています。
まず簡単なところから言うと、ライブラリの型が提供されていないものが多く、アプリケーションの型検査をするまでにライブラリの型を自分で書かなければならないことがよくあります。ライブラリの型情報を集約するリポジトリのgem_rbs_collectionを運用していますが、まだまだカバレッジが低く、型が書かれていないライブラリが多く残っています*11。このように依存関係を含めて、既にあるRubyプログラムの型を書くことに手間を取られ、型検査の利点を実感できるまでに時間がかかることも問題の一つです。
さらにSteepの動作が遅く、型検査に時間がかかり過ぎることも問題です。SteepはRubyで実装されている分、もっと速いプログラミング言語で実装する場合よりは不利なのですが、それはそれとしても遅過ぎます。RubyKaigi 2023ではShopifyのWebアプリケーションを解析するのに45分かかったことが報告されましたが、さすがに一つのプロジェクトを解析するために小一時間かかってしまうようでは実用的とは言えません*12。
Rubyプログラムに型を埋め込む
そして、第一の問題は型をRBSファイルという別のファイルに書かなくてはならない点です。これはRuby自身の構文を拡張しないで型検査を導入するという大方針から得られたものですが、やはり面倒です。二つのファイルを行ったり来たりしながら開発を行うのは単純に面倒ですし、コードレビューの観点でも問題があります。既存のメソッドを消すような場合にも、実装と型定義の両方を削除するのは面倒で、単に忘れてしまうことが頻発します。まずはここに手を入れて、Rubyコード自体にコメントとして型宣言を埋め込めるようにするための開発を進めています。
RubyKaigi 2024では、この新しいプロジェクトrbs-inlineについて発表しました。
先ほどの Arcitle クラスの型を、埋め込みRBSを利用して記述すると次のようになります。
class Article attr_reader :title #:: String attr_reader :content #:: String # @rbs title: String # @rbs content: String # @rbs returns void def initialize(title, content) @title = title @author = author @content = content end #:: () -> String def slug = title.gsub(/\s/, "-").downcase end
具体的な構文はまだ変更したいと考えていますが、大まかな見た目としてこんな感じになる見込みです。
聞いてくださった皆さんからのフィードバックはおおむね好評のようです。(ちなみにMatzはこのようにコメントとして型を埋め込むことには「黙認する」態度を取っています。)このまま開発を進めて、RBSとSteepを用いた型があるRuby開発をより快適で生産性の高いものへと発展させていくことが、現時点での私の目標です。
型はドキュメントである
先ほどRBSの設計における根拠の一つに挙げた「静的解析技術の発展によって、型を書く必要がなくなる」というMatzの主張は正しいのでしょうか?最後にこれについて検討したいと思います。
型は、開発者の意図によって与えられるものであり、「書かなくてよくなる」ということはないと思います。開発者がプログラムを書いていく中で、どういうプログラムを書くのかを実際のコードよりも抽象的に表現するものが型であり、その役目がツールの進化によってなくなるということは起きないと思います。「人間は抽象的なものを扱うことに集中して、詳細はコンピュータに任せる」というのがここまでのプログラミングを含むコンピュータ利用の発展の歴史であり、コードを先に書いて型はコンピュータに任せるというのはむしろ逆の流れです。
もちろん、現実には既に型が書かれていない膨大なRubyコードがあるわけで、これらをなんとかするというのは大きな課題です。この状況では、静的解析技術が進歩して型を生成できるようになることには大きな価値があります。一方で、それらに既に型がある程度与えられているという状況になってしまえば、コードと同様に型もプログラミングの中心的な存在になるはずです。
と言いつつも、Matzと私のどちらが正しいのかは、実はどうでもよいというのが面白いところです。私は、今すぐに型を書きながらRubyでプログラミングがしたいからSteepとRBSを作ったので(そして同じように考える人がそれなりにいそうなので)、Matzが予想する未来が来てもあまり影響はありません。逆に、もしも将来Matzが誤りを認める日が来たとしても、SteepとRBSによって静的型付けRubyプログラミングの実績がすでにあれば、その経験から必要な機能を上手くRuby自体に取り込んでいくことができるわけです。
とはいえ、Ruby本体に型検査のための構文・機能がある方がやはり良いので、それは今後も様子を見ながらやっていきたいと思います。
*1:https://dl.acm.org/doi/10.1145/582153.582176
*2:https://dl.acm.org/doi/10.1145/113445.113469
*3:https://cir.nii.ac.jp/crid/1050282812867199616
*4:http://scheme2006.cs.uchicago.edu/13-siek.pdf
*5:https://www.typescriptlang.org/
*6:https://github.com/ruby/typeprof
*7:https://github.com/ruby/repl_type_completor
*9:https://github.com/pocke/rbs_rails
*10:https://github.com/ksss/orthoses
*11:https://github.com/ruby/gem_rbs_collection
*12:https://rubykaigi.org/2023/presentations/Morriar.html#day3